阿里、百度、腾讯都选择 Flink,它到底有什么魔
开源大数据处理技术从 Hadoop 开始,经历了 Storm,Spark,现在又到 Flink 的发展过程,计算模型也经历了从批到流的转换,目前的新趋势也已经开始朝着批流融合方向演进。

从媒体的最新资讯推送,到购物狂欢的实时数据大屏,实时计算已经应用到了多个生活、工作场景,随着业务的快速增长,我们对实时计算的需求越来越高。
可用于实时计算的开源大数据计算引擎有多种选择,比如 Storm、Samza、Flink 等,而支持流批一体的只有 Spark 和 Flink。目前,多家企业已经或正在将计算任务从旧系统 Storm 迁移到 Flink,腾讯便是其中之一。
腾讯实时计算团队的任务是为业务部门提供高效、稳定和易用的实时数据服务。其每秒接入的数据峰值达到了 2.1 亿条,每天接入的数据量达到了 17 万亿条,每天的数据增长量达到了 3PB,每天需要进行的实时计算量达到了 20 万亿次。
其早期的实时计算平台基于 Storm 构建,但随着业务规模不断扩大,业务需求不断增多,原先的实时计算平台遇到了很多问题, Storm 的一些缺陷也渐渐暴露出来。在此背景下,腾讯实时计算团队选择用 Flink 替换 Storm 作为新一代的实时流计算引擎,对社区版的 Flink 进行了深度的优化,并在此之上构建了一个集开发、测试、部署和运维于一体的一站式可视化实时计算平台——Oceanus。
Storm vs Flink
为什么腾讯会转向 Flink?很简单,我们不妨来做下对比。
Storm
Storm 是一个免费、开源的分布式流处理计算框架,具有低延迟、容错、高可用等特性。它可以轻松可靠地处理无限数据流,是实时分析、在线机器学习、持续计算、分布式 RPC 、ETL 的优良选择。
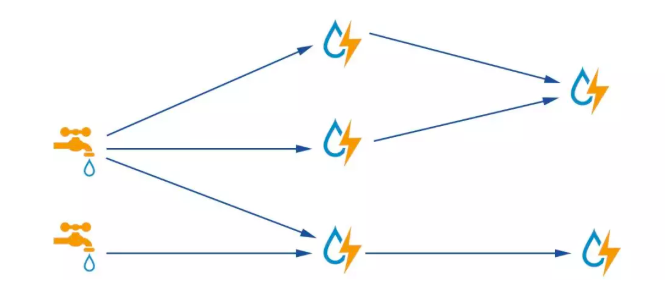
Storm 的拓扑(Topology)被设计为有向无环图(DAG)的形状。图表上的边缘被命名为 Stream,它是无限的元组序列,以分布式方式并行处理和创建,将数据从一个节点指向另一个节点。而这个图上有两种节点,一是 Spout,拓扑中 Stream 的来源,二是 Bolt,拓扑中的所有处理都是用它完成的。Topology 类似于 Hadoop 的 MapReduce,但有一个关键的区别,Storm 拓扑会永远运行,除非你杀死它,而 MapReduce 作业必定结束。
主要特性:
极其广泛的用例:可用于流处理、连续计算、分布式 RPC 等等
可扩展:要扩展拓扑,您所要做的就是添加机器并增加拓扑的并行度设置
保证不丢失数据:实时系统必须对成功处理的数据有很强的保证,而 Storm 能保证每条消息都会被处理
容错:如果在执行计算期间出现故障,Storm 将根据需要重新分配任务。Storm 确保计算可以永久运行(或直到你终止计算)
编程语言无关:Storm 拓扑和处理组件可以用任何语言定义,几乎任何人都可以访问 Storm
缺点:
无状态,需用户自行进行状态管理
没有高级功能,如事件时间处理、聚合、窗口、会话、水印等
详见:
https://github.com/apache/storm
http://storm.apache.org/index.html
Flink
Flink 是一个同时面向数据流处理和批量数据处理的开源框架和分布式处理引擎,具有高吞吐、低延迟、高扩展、支持容错等特性。
其以数据并行和流水线方式执行任意流数据程序,流水线运行时系统可以执行批处理和流处理程序。此外,Flink 的运行时本身也支持迭代算法的执行。

主要特征:
流批:流媒体优先运行时,支持批处理和数据流程序
优雅:Java 和 Scala 中优雅流畅的 API
高吞吐和低延迟:运行时同时支持非常高的吞吐量和低事件延迟
容忍数据的延时、迟到和乱序:解决基于事件时间处理时的数据乱序和数据迟到、延时的问题
灵活:非常灵活的窗口定义
容错:提供了可以恢复数据流应用到一致状态的容错机制
背压:流媒体中的自然背压
缺点:
社区不如 Spark 那么强大,但在快速成长
流处理远远流行于批处理
详见:
https://flink.apache.org/flink-architecture.html
https://github.com/apache/flink
哪些公司被 Flink 吸引?

去年年底,一份市场调查报告显示,Flink 是 2018 年开源大数据生态中发展“最快”的引擎,和 2017 年相比增长了 125% 。目前,全球有多家企业正在使用 Flink,比如 Amazon 的 Amazon Kinesis Data Analytics 是一种用于流处理的完全托管的云服务,它部分地使用 Flink 来支持其 Java 应用程序功能。Ebay 的监控平台由 Flink 提供支持,可评估数千条关于指标和日志流的可自定义警报规则。除此之外,还有 Uber、Yelp 和 CapitalOne 等公司也是 Flink 的用户。
国内也有很多公司在使用 Flink ,我们在查询相关资料时发现,部分公司正是从 Storm 迁移到 Flink 的,比如前面我们提到的腾讯,还比如:
阿里巴巴:阿里巴巴在 2015 年开始尝试使用 Flink,但因当时 Flink 面世不久稍显稚嫩,阿里巴巴在 Flink 的基础上维护了一个内部版本的实时计算平台 Blink,以满足自身超大体量的业务需求。今年 1 月 28 日,Blink 被正式开源。在此之前,阿里巴巴使用的是 JStorm,与 Blink 相似,JStorm 是阿里巴巴用 Java 语言代替 Clojure 语言重写的 Storm,在原有基础上做了不少优化。JStorm 也是阿里巴巴开源的几个明星产品之一。
字节跳动:字节跳动的多个业务曾跑在 JStorm 计算引擎上,但集群过多等问题比较明显,考虑到 Flink 可以解决相关问题,且能兼容 JStorm,字节跳动便将 JStorm 任务迁移到了 Flink 上。
有赞:实时计算在有赞的发展路程和大多数互联网公司一样,是从早期的 Storm,到 JStorm,Spark 再到 Flink。2014 年,第一个 Storm 应用在有赞内部开始使用;2016 年,有赞使用 Spark ;2018 年,有赞在实时平台中增加了对 Flink 引擎的支持。
饿了么:饿了么的实时计算平台演进之路也是从 Storm 到 Spark,后来基于平台的发展,选择了拥抱 Flink 。
苏宁:与饿了么相同,从 2014 年到现在,苏宁的实时计算平台经历了从 Storm 到 Spark 再到 Flink 的演进。
美团:美团在实时计算系统建设初期部署的是 Storm,随着业务对实时数据的需求激增, Storm 无法跟上业务发展,经过调研,美团发现 Flink 的吞吐性能比 Storm 有显著提升,遂更换选型。
唯品会:目前,唯品会的实时计算平台并非统一框架,而是 Storm、Spark、Flink 三者共用。其中, Storm 作业最多,但是其业务重心正逐渐转变到 Flink。
除了上面我们提到的,应用 Flink 技术的公司还包括百度、携程、滴滴等。
实时计算技术演进
开源大数据处理技术从 Hadoop 开始,经历了 Storm,Spark,现在又到 Flink 的发展过程,计算模型也经历了从批到流的转换,目前的新趋势也已经开始朝着批流融合方向演进。此外,随着 Presto,Impala,Kylin 和 Druid 等新兴 OLAP 技术的出现,也为实时数据分析增加了丰富的解决方案。

时间:2019-04-24 14:20 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















