为什么每个数据科学家都要读一读Judea Pearl
《The Book of Why: The New Science of Cause and Effect》(为什么:因果关系的新科学)是人工智能先驱、贝叶斯网络之父 Judea Pearl 的一本著作,是作者对自己过去 25 年在因果关系方面所做研究的一次总结。这本书颇具启发性,以至于本文作者读过之后忍不住向所有人推荐。

我热衷于机器学习已经有 4 个年头,对深度学习感兴趣也有一年了。我构建了用于娱乐和工作的预测模型,也了解很多算法,从梯度提升(gradient boosting)这种传统模型到LSTM这种很深的模型。尽管习得了很多算法,但是我的困惑依然存在。
算法自己也无法解决的困惑
如果你不是那种只关心 0.01% 的错误率降低,而是努力使自己的模型有意义的数据科学家,你可能一次又一次地这样问自己:
♦ 我应该把这个变量添加到模型里面吗?
♦ 为什么这个反直觉的变量会作为一个预测结果出现?
♦ 为什么当我增加另一个变量的时候这个变量就会突然变得没有意义?
♦ 为什么相关性的方向与我所认为的会相反呢?
♦ 为什么我所认为的一个很高的相关性结果却是零相关呢?
当我将数据分解成几个子部分的时候,为什么关系的方向会反过来?
随着时间的推移,我已经建立了足够的意识来解决这些基本问题,例如,我知道双变量关系和多变量关系可能是非常不同的,或者是数据受到了选择偏差的影响。但我还是缺乏一个坚定的框架来确定地说服我自己和其他人。更重要的是,或许直到关系和我的想法矛盾的时候我才会意识到!值得注意的是,当某件事情出现矛盾的时候,说明它早已出了严重的偏差。如果没有地图,怎么才能在意识到迷路之前确定我走的方向有没有问题呢?
没错,关联和因果关系都是可以预测的
当我读了 Judea Pearl 的《为什么:因果关系的新科学》这本书之后,这个困惑完全消除了。现在它已经成为我的数据科学指南了。在本文中,我会简要地介绍一下这本书。简言之,它就是在讲因果——原因与结果之间的关系。有两种方式可以预测未来的某件事情:
♦ 我知道当 X 出现的时候,Y 也会出现(关联)
♦ 我知道 X 会导致 Y(因果)
这两种方式都可以用于预测。两种方式都可以得到相似的模型性能。所以,它们有什么不同呢?为什么要费心理解因果关系呢?如果它是一个强大的工具,那么因果关系可以通过数据来研究吗?
随机对照实验为何有时候并不可行?
作为一个黄金准则,随机对照试验(RCT)(也就是市场营销中所谓的 A/B 测试)被用来进行因果测试。在临床试验中,这项技术被用来研究某个特定的药物/治疗方法是否能够改善健康。
随机就是为了最小化选择偏倚,所以我们知道,我们不会特意选择病情更严重的病人来应用某种治疗方法,这种做法明显收益更低,如果我们不选择病情更严重的病人收益要更高。控制变量起到了基准的作用,以便我们比较接受了治疗和没接受治疗的病人。作为一个标准,这里也有一个所谓的双盲机制,病人不知道他们是否接受了治疗,这是为了避免心理作用。
尽管这是一个黄金准则,但是它在某些条件下可能是不切实际的。例如,如果我们想研究吸烟对肺癌的影响,很显然我们不能强迫某人去吸烟。另一个例子就是:如果我想知道读博对我的人生有多大的促进作用,那肯定也不能进行对照实验,因为时间一去不复返。毕竟,一项实验会有很多限制,例如,样本是否能够代表全体?是否是合乎道德的?等等。
从观察的数据到因果分析?
如果开展实验是不现实的,那么我们可不可以使用观察到的数据来研究因果关系呢?观察到的数据意味着我们不能做任何干预,我们只能观察。这是否可能呢?
不管是否了解统计,你可能都听过这个说法:相关性并不意味着因果关系。但是,它并没有告诉你如何研究因果关系。好消息就是,在阅读完这本书之后,你会得到一个更好的框架,利用它判断如何研究因果关系,以及决定何时可以/不可以利用手头的数据来做研究,这样一来你就知道应该收集什么数据了。
这本书中的一些观点
我在这里并不展开具体的技术或者公式。一方面,我只是读完了这本书,并不是因果关系方面的专家;另一方面,我鼓励你读这本书,以防错过任何一个见解,因为我也可能是有偏见的。
尽管大数据很重要,但是将所有的东西都添加到你的模型中或许并不可行。
大数据时代几乎拥有无限的计算力和数据,你或许想要将所有的数据都放到一个深度神经网络中来进行自动特征提取。我也受到了这种诱惑。
这本书告诉了你一些关于添加变量的注意事项。例如,你想要预测 Z,而且基本的关系是 X→Y→Z(箭头代表的是「导致」,在这里 Y 是一个中间变量,它连接着从 X 到 Z 的作用)。如果你将 X 和 Y 作为模型的变量添加进去,Y 可能会吸收所有的「解释力」,它会将 X 从你的模型中踢出去,因为从 Z 的角度来看,Y 比 X 更加直接。这便阻碍了你研究从 X 到 Z 的因果关系。你或许会说,这在预测上是没有区别的,不是吗?从模型性能的角度来看的确是这样的,但是,倘若我告诉你 Y 离 Z 是如此之近,以至于当你知道 Y 的时候,Z 已经发生了,这将如何?
同样,不添加某些变量也是有风险的。你可能听过伪相关或者混杂变量这个术语。基本的思想可以在这个关系中描述:Z←X←Y(也就是说,X 是一个混杂变量)。注意这里的 Y 和 Z 之间是没有因果关系的,但是如果你不考虑 X 的话,Z 和 Y 之间就会出现一个关系。一个著名的例子就是巧克力消费量与诺贝尔奖获奖数之间的正相关关系。结果这两者的一个共同影响因素是国家的富裕程度。同样,你可能认为预测没有问题,但是你可能很难向别人解释你的模型。
当然,世界远比我们想的复杂,但是这就是领域知识发挥作用的地方。因果图是有关事物如何运作的简单而有力的表征。
书中还有很多高级的脑筋急转弯和现实生活的例子。
因果关系或许更加鲁棒
因果关系可能随着时间发生变化。如果你希望模型一直是鲁棒的,可以建立 Z←X→Y 这样的模型。在这个模型中,由于你建模的是 X → Y,所以如果关系 Z←X 变弱了,你并不会受到影响,但如果你在 Z 和 Y 之间建模就会受到影响了。
从另一个角度来说,如果我们相信因果是比关联更强的一种关系,那么这意味着,当我们从一个领域借用到另一个领域时,那种关系更有可能保持。正如书中所提到的,这就是所谓的迁移学习/可迁移性。书中引用了一个关于可迁移性的非常富有见解的例子,它描述了我们如何以可见的方式进行调整,以便将因果关系从一个领域迁移到另一个领域。
干预变得更加容易了,尤其是在数字时代
干预实际上是研究因果关系最重要的动机之一。通过仅仅学习关联得到的预测模型不能给你提供关于干预的深入见解。例如,在 Z← X → Y 这个关系中,你不能改变 Z 来影响 Y,因为它们没有因果关系。
如果你能理解基本关系的话,干预本身就是一个更为强大的工具。这意味着,你可以通过改变管理策略来让我们的世界变得更加美好;你可以改变治疗方法来拯救更多的病人,等等...... 这就是你拯救病人和预测病人会死但不能干预之间的区别!或许这是数据科学家能做的最好的事情,只需要这个工具就行。
在这个数字时代,干预并不费力,而且确切的是,你有很多数据来研究因果关系。
这就是我们推理的方式,也或许是通向真正人工智能的道路
最后是关于人工智能的内容。推理是智能的必要部分,这也是我们的感觉。在闭环的世界中,强化学习在预定义的奖励和规则下通过平衡探索和开发能够实现卓越的性能,并且,在这种机制下,采取的动作能够改变状态,状态反过来又能够决定奖励。在这个复杂的世界中,保持这种机制有点不太可能。
从哲学角度来说,我们应该理解我们做出决定的方式。最有可能的是,你会问「如果我这么做了,会发生什么;如果我那么做了,又将如何?」。请注意,你仅仅是创建了两个并没有发生的幻想世界。有时候当你为了从错误中学习而做一些反思时,你可能会问:「如果我这么做了,那件事就不会发生。」再一次,你创建了反事实的世界。事实上我们比自己想像的更有想象力。想象的世界都是基于因果关系建立的。
也许机器人有它们自己的逻辑,但如果希望它们能够像我们一样,就要教会它们推理。这让我想起了 DeepMind 发表过的一篇论文——《Measuring abstract reasoning in neural networks》(在神经网络中衡量抽象推理),这篇论文证明,将推理作为训练数据的一部分能够增强泛化性能。我深受此文启发,这正是我们教机器人推理的例子!这也是在模式上从关联到推理的一次跳跃。
我猜测:因果关系对泛化是有帮助的。虽然我没有证据,但这就是我们理解世界的方式。我们学习了一两个例子,然后学习因果关系,再然后我们将因果关系应用在我们认为可以用到的任何地方。
将所有的东西放在一张因果图中,或许推理就是 IQ 测试问答中的混杂变量?我们是不是可以这么认为:推理导致人在问题中设计这种模式,它也「导致」了问题的答案?或者,它是将问题转换成推理的中间媒介,推理反过来又导致了问题的答案?或者可能两者都是?请注意,我刻意假设问题和答案之间没有因果关系,因为它们只是单纯的模式关联。
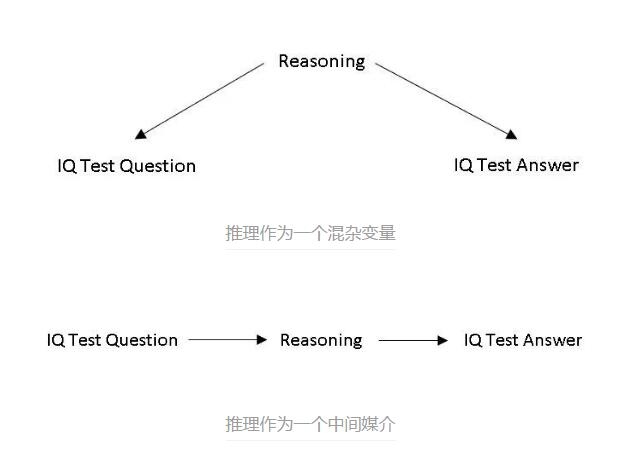
这一切仅仅是我的猜想。我不知道答案是什么。我不是一个专业的研究者或哲学家。但是我可以确定的是:当我们在解决问题的时候,因果关系提供了一个新的角度。因果关系和深度学习之间的协同听起来很有前景。
结语
我承认这篇文章的主题或许有些激进,但是我觉得自己有责任向所有的人推荐这本书。它告诉了我们因果关系的全部潜力。因果关系是与生俱来的,但是在大数据时代我们却忽略了它。这个框架已经存在了。只是有待于部署和付诸实践。
作为一名从业者,我相信我会使用这个工具产生更好的影响。
扩展阅读:观点 | 专访贝叶斯网络之父 Judea Pearl:我是 AI 社区的「叛徒」
原文链接:https://towardsdatascience.com/why-every-data-scientist-shall-read-the-book-of-why-by-judea-pearl-e2dad84b3f9d

时间:2019-03-20 23:05 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















