企业大数据的现状与痛点——《企业大数据实践
内容分类:
1、 企业大数据现状及痛点
2、 大数据对企业的促进作用
3、 解析业务数据的特征
4、 典型技术架构的分析和构建
前三个为铺垫类,最重要的是第四个。但前三个的重要性也非常高,把目录调整下变成目标B,再来看就比较清楚:

1、 找出问题,才能解决问题;
2、 计算收益,大多数都是做企业型的,而非学术型,所以收益是企业必不可少要考虑的,并且也是要痛点痛到不能呼吸时,大多企业才会花费大量的精力去解决,而不是无关痛痒的东西也拿来占用大量企业资源解决,这样一定情况上会影响业务增长与企业生存,这一点也是非常重要的;
3、 分析病灶,找到瓶劲,制定应对措施;
4、 给出解决方案,制定计划,对症下药,解决问题。这一点是最最重要的,涉及到架构搭建以及套路化的解决问题方法论。
下面就重点介绍目录1的所有内容:如何发现问题。
一、大数据的概念
很多人都在听大数据如何如何,怎样怎样。但大数据到底是怎样的,并不是非常清晰。从表面现象来看,大数据是一个海量数据,但问题在于我们要让这些海量的数据产生价值,就要通过一些挖掘工具来寻找它的价值 ,这是大数据尤为重要的方向。
大数制的标准定义:
1、从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。
2、大数据的特色在于对海量数据进行分布式数据挖掘,其战略意义不在于掌握庞大的数据信息,而在于对这些有意义的数据进行专业化处理。
3、如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过加工实现数据的“增值”。
大数据和云计算之间的关系是一体两面的,没有云计算就没有大数据。
二、大数据的前世今生
无论是大数据还是云计算,都有一个非常重要的角度,2004~2007这三年,谷歌发布了三篇论文,引爆了大数据时代的降临。
这三篇论文是基于分布式数据库、分布式文件系统,以及弹性计算,它纯属理论,研究报告。
到了2008年,大数据之父”道格 · 卡丁把谷歌的三篇论文从理论变成了稳定产品。就是HADOOP生态逐渐起来。
2012年,联合国、中、美等国发布大数据白皮书。阿里巴巴设立首席数据官一职。原来只有CIO,没有CDO,这也是从2012年之后才开始流行起来,有CDO这个职位。

三、本期内容的重要环节:企业数据现状及痛点
数据的收集分三类
客户端数据收集
业务端数据收集
服务端数据收集
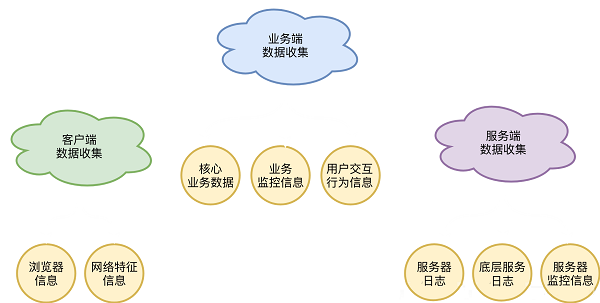
一)客户端的数据收集主要分两种:浏览器信息的收集/网络特征信息的收集,能收集到的和已收集到的基本上也就这两类。
1、浏览器信息主要通过浏览器请求过来,通过服务器抓包日志里面的一些信息,包括它使用的什么浏览器、请求的参数、cookie等等,这样的数据都是通过浏览传过来的,这部分信息也是比较容易获取的。
2、网络特征信息,存在CS架构程序里面,BS主要是拿浏览器信息,而CS主要通过网络特征信息把它传过来,传到服务器的同时传到日志里面去,这就是整个客户端数据收集层面的数据。
二)业务端数据收集,是比较泛的,可以收集到核心业务数据和业务监控数据以及用户交互行为信息三部分的数据。
这些数据如何定义,分别代表什么?
1) 核心业务数据:整个数据的业务信息,如果你是做电商的,像商品信息、购买信息、订单信息、用户信息都是核心业务数据;
2) 业务监控信息:像流量统计,库存报警,短信发送量监控、账号资金池余额监控,退换货等信息;
3) 用户交互行业信息:如果一个用户在你这里查看了一件商品,阅读了一篇文章等信息,它不是很敏感,也不是很核心的信息,只是用户在操作中产生的一个交互数据,这个数据可能是有目的性的,比如他是需要买这件商品,所以他会浏览,也可能是没有目的性的,比如他可能是无意中点进来看看就走了。但是我们的交易信息一般都存在库里面,但也可能是有,你没有收集落地,但却可以被收集。
三)服务端数据收集:分为三个部分的数据:服务器日志/底层服务日志/服务器监控信息
1、服务器日志收集:无论是使用Windows服务器或是Linux服务器,服务器的日志都是非常关键的,同时比较容易收集,但也存在麻烦,它不单纯是服务器有一个什么日志在某个地方,而是有无数个小服务,无数个核心服务组成的一个日志库,就比较庞杂,会有各种各样的服务及应用。
2、底层服务日志:今天在我们的服务器上运行的一个网站,网站可能是通过我们的Apache去暴露的, 也可能是通过Nginx暴露出去的,Apache和Nginx是一个底层服务,它会产生很多很多的日志,这个日志是我们非常重要的一个分析源,是可以被收集的,也有很我公司收集这些数据进行分析。
举个例子:通过分析Nginx日志了解到哪些页面的性能是瓶颈,我的业务系统里面有200个页面,其中有15个页面,响应时间是超过2~3秒钟,这种情况明显是不正常的,就需要进行性能优化处理,这是一种可能性。
第二种可能性:如果系统出现了问题,被攻击,或入侵等问题,可能通知日志去分析哪些页面可能成为入侵的一个点,或口子,包括有没有一些畸形的请求产生,这些都是可以通过服务日志里面看到的,这些分析也是非常重要的,一切的分析都是离不开日志的。
3、服务器监控信息:现在软件越来越多了,都具备收集监控日志的能力,比如做监控开源用的比较多的有Zabbix,还有阿里云的云监控,都是相对用的比较多的,它能监控我们整个服务器CPU的使用,磁盘的使用以及内存的使用,IO的开销等等,不一定是日志的方式去落地的,但会有一个程序去收集它,把数据发送到他的服务端上去。整个服务端收集到的数据都非常的丰富与多元化,也非常庞杂。
那么以上数据能收集到的三大块数据里面的8小块信息又都有怎样的表现形式呢?
客户端数据样例:
从下图中可以看到时间、类型、页面地址、浏览器类型以及版本号、设备信息等,都是非常重要的信息。

这些信息通常来源于对浏览器信息的采集,信息多为非结构化数据,而且量特别大。当业务表现为WEB形式时,通常拿到的数据是浏览器的相关信息,当业务表现为混开式APP时,拿到的数据会额外得到业务APP的其它信息,比如机型、Android或IOS版本号等。
业务端的数据样例:
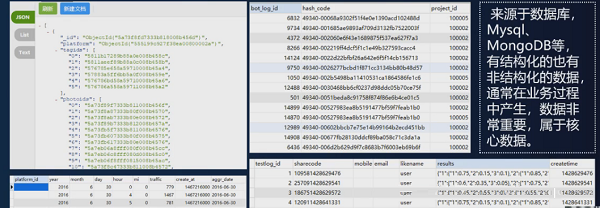
上图来源于数据库,Mysql、MongDB 等,有结构化的也有非结构化的数据,通常在业务过程中产生,就如之前讲的如果你是做电商平台的,那这些数据就是电商运作过程中产生的数据。这些数据非常重要,属于核心数据,重要性远远大于客户端数据和服务器端数据。
可以肯定的说,其它两个数据丢也就丢了,不会给公司造成致命性的伤害,但业务数据如果丢失了,可能公司都没了,重要性可想而知。
服务端的数据样例:
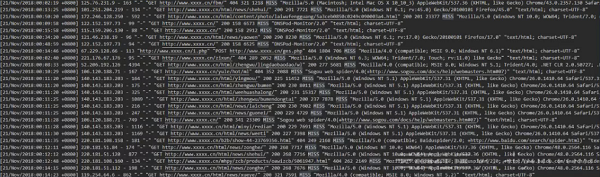
通常来源于服务器端的具体服务,一般为文本格式,且多为非结构化数据,比较枯燥,上图这个日志就是一个Nginx的访问日志,这里面也存在一些比较有差异化的地方。当前用的软件都是比较新的,但有一些存量的业务使用的版本偏老,这种情况就会存在同一个业务线使用了不同的底层服务,比如说Apache可能使用了2.2的版本,也有可能使用2.4的版本,Nginx有可能使用了1.1的版本,甚至是1.0的版本,这种版本上的差异会带来如几个弊端:
1、 配制方式不一样
2、 日志格式不一致:这种情况就会导致不同时期、不同版本的服务可能产生格式完全不一致的日志,导致模板无法套用,这是一个需要引起注意的问题。服务端的数据相对说比较单纯,多半都是文本形式存在。
以上三大类8小块的数据,这些数据都有些什么样的问题?这个是需要我们任何一个人去思考的。
四、数据存在的问题
大部分企业的数据现状,基本上就分如下四个部分,当然也有做好的,可能不存在如下这种情况,但绝大数据情况下,都多少会有一些问题。而我们本身就是一个有问题的企业,一步步从有问题到发现问题、解决问题这样摸爬滚打过来的。
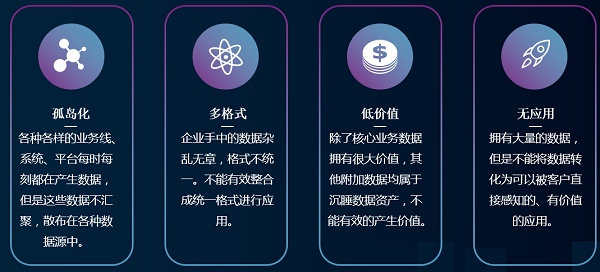
1、孤岛化:各种各样的业务线、系统、平台每时每刻都在产生数据,但是这些数据不汇聚,深入点讲就是数据可能都不在一台服务器上,业务起来也有先后顺序,不一定都集在一套系统里成。最常见的像用Java做的应用程序,几年前开发的是一个IIS一个版本,Tomcat一个版本,今天开发的产品用的IIS是一个版本,Tomcat又是一个版本,这种问题理论上说是要优先考虑并且要避免的,要对老的版本进行迭代,保持到一个比较新的且稳定的版本,但大部分企业都聚焦在如何把业务更快速的迭代好,把产品上线,很多东西就在过程中慢慢孤岛化。除了IIS与Tomcat外,像Mysql、日志平台的差异等,如果不能有效的统一起来,就无法有效的进行数据分析,这就是孤岛化带来的最大问题。
2、 多格式:企业手中的数据杂乱无章,格式不统一。不能有效整合成统一格式进行应用。如果今天我们要去分析我们的数据,数据要拿来用了,我们都希望数据统一,无论是结构化还是非结构化,大不了JS我们打散放到MongDB里面去,变成一个个文档到后面再去处理,要么就是全部都处理好变成结构化数据,放到一个Mysql,或者是其它结构化的数据里面,再进行统一的分析和处理,但这种状态太理想化了,很难实现,像返回日志的问题,有1000条PV就会有1000条日志,如果这是1天的量,那一年的量可想而知,这样的数据量放到单一的数据库里面去,也不现实,所以多格式面临的问题就是不能有效的整合成统一格式进行应用。
3、 低价值:除了核心业务数据拥有很大价值,最大的问题是所有业务数据的量只占我们所有数据量的5%~10%,其他90%都是附加数据,不能有效的产生价值。所以大数据从字面意思理解,他只是一个名词,是一个海量数据的名词,90%数据都不产生价值的话,它只能属于沉睡数据资产。大部分企业数据都存在这个问题就是低价值的问题。
4、 无应用:拥有大量的数据,90%的数据又不能被直接应用,无法被用户直接感知,它就是我们经常所说的,食之无味,弃之可惜,但又占用空间的无用产物,无应用就体现在占用磁盘,应用了你大量空间,却未被转化成客户可感知、可应用的数据。
五、内容总结
1、大数据的概念
2、大数据的前世今生
3、大数据的采集方式
4、数据的定义
5、数据存在的问题
六、问题答疑环节:
1:大数据在高校里面有什么样的应用场景?
答:
1)实验数据少时,用纸记录;
2) 产生海量数据时,找个数据库存下来,会存在几个比较明显的问题:
A、 实验室比较机动,随机性强,数据格式无法定义
B、 数据不标准,多数情况下先收集,再分析
问题2:业务数据难道不是通过客户端收集的吗?
答:
业务数据不一定是通过客户端收集的,如果你的产品是通过异步方式处理的,APP端和WEB端只负责请求丢给消息队列,由后端服务去消费消息队列,再进行后续的操作,这个过程中你是可以去收集消息队列中的日志,再进行分析,从而留存用户行为的效果。
通过客户端收集会有一个问题,收集日志过程中都有一个原则,如果是通过非侵入式拿到日志,那就一定得通过非侵入式获取日志,千万不要通过破坏性的埋点、打空的方式拿日志,埋点打空本身会对我们的业务形成一定的破坏性,影响到性能,特别是不能预期这个场景时,这个性能破坏无限大。比如说当你在做一个秒杀活动的时候,你通过秒杀活动的APP同步参与秒杀,又同时存日志到数据池中去,秒杀可能有1秒中有几十万次,几百万次的请求,服务器本身压力已够大,这种情况下,可能就会导致雪崩,集群有可能就会挂掉。这是一个非常典型的,不应该出现的低级错误,所以最好是庞路收集。

时间:2019-02-22 22:25 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















