云原生or本地?一家全球6大数据中心企业的大数
当我们讨论一家企业的技术架构选型时,通常会涉及几大指标:可用性、可靠性、性能和成本。近几年,随着的发展,我们也会加上云原生服务。其中,有些指标是与业务场景紧密相关的,比如可用性和可靠性;有些指标则与企业决策相关,比如成本和性能之间的平衡。FreeWheel是一家跨全球有六大的高端视频广告管理技术和服务提供商,这样一家面对跨区域、高可用、高容灾业务场景的企业,其大数据架构选型的前、中、后期是如何进行的呢?
FreeWheel公司总部位于美国硅谷,在纽约、旧金山、芝加哥、伦敦、巴黎、北京等地分别设有分支机构。其中,FreeWheel北京分公司作为全球研发中心,负责公司核心产品研发。从最初的C++、手写ETL流程到现在大数据平台、容器化和,FreeWheel架构师张磊揭示了选型前后的心路历程。
选型前——架构和成本的评估
关于技术选型,FreeWheel一直希望在可用性、成本(包括学习成本,运营成本和维护成本)和性能之间寻求平衡。而即使已经完成了技术选型,在迁移现有平台至AWS这类云服务时同样要重新考虑这些因素。其原因一是自建机房的那一套解决方案可能并不适合原样照搬到云平台上;二是云服务提供商本身提供了很多托管的解决方案,孰优孰劣还需要重新评估。
对企业而言,一个好的架构首先要能满足当前的业务需求,其次是能够根据业务和技术的发展,具有可持续改造和升级的能力。技术选型时,架构师需要评估接下来一段时间内的业务发展规模及需求,根据团队的技术积累和技术方向,学习调研各种可能的解决方案是否能够并适合解决当前面临的问题。同时,再好的架构也不可能一蹴而就,一劳永逸。所以在日常工作中还需要不断探寻是否存在更有效的方案,从而对架构进行升级。
对于具体的技术实现,以开源技术组件为例,架构师需要考虑的方面包括组件的成熟度是否合适,社区是否活跃,同时需要考虑新技术的学习成本、迁移成本和运营成本是否可以承担等等。而对于云服务迁移来说,还面临着云服务生态等更多需要考虑的因素。毕竟一家企业在选定某个云服务平台以后,再更换的成本将是非常巨大的。
搭建中——成本or性能?
一旦前期技术选型基本确定,中期的主要工作就是具体实施,但在实施的过程重往往还是会遇到一些现实的问题。
以FreeWheel的大数据平台为例, 虽然FreeWheel目前几乎所有的数据处理均在AWS上完成,但是在设计伊始,考虑到在一段时间内整个平台还会是自建机房和AWS上共存的局面,以及一些关键的性能评估,我们在AWS上还是选用了与自建机房类似的基于Hadoop, HBase,Kafka和Presto的解决方案。
即便是这种看似无缝的迁移,在实际构建过程中,还是遇到了很多棘手的问题。以高可用的设计为例,AWS因为涉及到自身就高可用服务、可用区、区域这些概念,加上跨可用区/跨区域收费这样的额外成本,在其中的高可用设计和在自建机房可能会有区别。这就需要在具体实施中根据业务的特点设计出尽可能平衡可用性,成本和性能的解决方案。
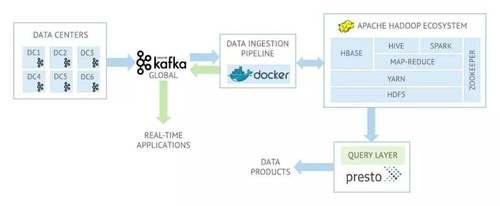
FreeWheel大数据平台架构简图
首先,我们会尽量利用AWS高可用的原生服务,这是最简单也是十分有效的手段。例如使用EBS作为Kafka的存储介质。这样即使Kafka Broker所在的物理机出现故障,其数据还是可以恢复的。
而对于Zookeeper、Kafka Broker、HBase等服务,需要根据其自身不同特性做分别处理。其中,因为Zookeeper的体量和数据交换都比较小,可以直接采用类似三可用区五副本的方案解决。
Kafka Broker相对来说会复杂一些。如果单纯为了高可用将Kafka都部署成三可用区五副本当然是可以的。需要考虑的是AWS的跨可用区数据传输是收费的。这个收费看起来可能不贵,但考虑到写内容时Kafka内部要做副本的数据同步,而客户端读取内容的时候也是无差别的跨可用区读取,对于处理海量消息来说,数据传输成本就会成为不得不考虑的因素了。
基于此,FreeWheel对Kafka上处理的业务进行了分级处理,保证像花费反馈这类关键任务完全的高可用,而对数据量较大或对可靠性要求可以适度放宽的业务(比如一些离线业务),做了主从更改。默认情况下,应用和leader会在同一可用区,并且只从这个可用区读取数据,在节省传输开销的同时提升性能。而一旦某个或某些leader发生故障,系统可以自动切换至另一可用区,保证服务继续。
在HBase层面,我们在一开始也准备效仿Kafka的实现方式。但经过反复试验,仔细权衡了传输开销和运营维护成本之后,我们决定对HBase使用两个可用区的无差别化处理的解决方案。
迁移上云后——云原生or本地?
如今,国内外可提供云平台的厂商不在少数,企业势必会面临一个选择——到底是选用云服务厂商已经构建好的服务还是选择在云上自行搭建?基于FreeWheel在AWS上经验,张磊认为,对于没有历史包袱的企业,或者说对于数据量不是很大,业务不是很复杂的企业,可以考虑直接上云并根据业务特点和数据量尽可能地使用原生服务,因为这样可以提高效率并且降低运维成本。而对于已有技术栈和技术积累的企业而言,如果确定要往云端迁移,需要综合考虑云上解决方案,争取最大化云服务的价值。
选型后——总结调整
当平台已经搭建完成,架构师还需要做的工作就是总结调整,适时迭代。FreeWheel在接下来一段时间倾向于持续性改进和局部优化。例如,我们还是会坚持以Presto为核心组件的查询引擎,但是会不断调研实践,以改进其性能。
综上,FreeWheel在集成了全球90多个服务器端,6大数据中心,日均10亿日志的场景下,保障了业务的高效运行。
相关阅读:

时间:2018-12-20 23:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















