解读 2018:13 家开源框架谁能统一流计算?

本文是实时流计算 2018 年终盘点,作者对实时流计算技术的发展现状进行了深入剖析,并对当前大火的各个主流实时流计算框架做了全面、客观的对比,同时对未来流计算可能的发展方向进行预测和展望。
今年实时流计算技术为何这么火
今年除了正在热火落地的 AI 技术,实时流计算技术也开始步入主流,各大厂都在不遗余力地试用新的流计算框架,升级替换 Storm 这类旧系统。上半年 P2P 狂想曲的骤然破灭,让企业开始正视价值投资。互联网下半场已然开始,线上能够榨钱的不多了,所以,技术和资本开始赋能线下,如拼多多这类奇思妙想剑走偏锋实在不多。
而物联网这个早期热炒的领域连接线上线下,如今已积累的足够。物联网卡包年资费降到百元以下,NB-IoT 技术的兴起在畜牧业、新农业、城市管理方面都凸显极大价值。各大厂都在血拼智能城市、智慧工厂、智慧医疗、车联网等实体领域。但,这些跟实时流计算有几毛钱的关系?
上述领域有一个共同的特点,那就是实时性。城市车流快速移动、工厂流水线不等人、医院在排号、叫的外卖在快跑,打车、点餐、网购等等,人们无法忍受长时间等待,等待意味着订单流失。所以,毫秒级、亚秒级大数据分析就凸显极大价值。流计算框架和批计算几乎同时起步,只不过流计算现在能挖掘更大的利益价值,才会火起来。
实时流计算框架一览

目前首选的流计算引擎主要是 Flink 和 Spark,第二梯队 Kafka、Pulsar,小众的有 Storm、JStorm、nifi、samza 等。下面逐一简单介绍下每个系统优缺点。
Flink 和 Spark是分布式流计算的首选,下文会单独对二者做对比分析。
Storm、JStorm、Heron:较早的流计算平台。相对于 MapReduce,Storm 为流计算而生,是早期分布式流计算框架首选。但 Storm 充其量是个半成品,ack 机制并不优雅,exactly-once 恰好一次的可靠性语义不能保证。不丢数据、不重复数据、不丢也不重地恰好送达,是不同可靠性层次。Clojure 提供的 LISP 方言反人类语法,学习成本极为陡峭。后来阿里中间件团队另起炉灶开发了 JStorm。JStorm 在架构设计理念上比 Storm 好些,吞吐、可靠性、易用性都有大幅提升,容器化跟上了大势。遗憾的是,阿里还有 Blink(Flink 改进版),一山不容二虎,JStorm 团队拥抱变化,项目基本上停滞了。另起炉灶的还有 twitter 团队,搞了个 Heron,据说在 twitter 内部替换了 Storm,也经过了大规模业务验证。但是,Heron 明显不那么活跃,乏善可陈。值得一提的是,Heron 的存储用了 twitter 开源的另一个框架 DistributedLog。
DistributedLog、Bookkeeper、Pulsar、Pravega:大家写 Spark Streaming 作业时,一定对里面 kafka 接收到数据后,先保存到 WAL(write ahead log)的代码不陌生。DistributedLog 就是一个分布式的 WAL(write ahead log)框架,提供毫秒级时延,保存多份数据确保数据可靠性和一致性,优化了读写性能。又能跑在 Mesos 和 Yarn 上,同时提供了多租户能力,这跟公有云的多租户和企业多租户特性契合。Bookeeper 就是对 DistributedLog 的再次封装,提供了高层 API 和新的特性。而 Pulsar 则是自己重点做计算和前端数据接入,赶上了 serverless 潮流,提供轻量级的 function 用于流计算,而存储交给了 DistributedLog。Pulsar 在流计算方面有新意,但也只是对 Flink 和 Spark 这类重量级框架的补充。笔者认为,Pulsar 如果能在 IoT 场景做到舍我其谁,或许还有机会。 Pravega 是 Dell 收购的团队,做流存储,内部也是使用 Bookeeper,主要用于 IoT 场景。四者关系大致如此。
Beam、Gearpump、Edgent:巨头的布局。三个项目都进入 Apache 基金会了。Beam 是 Google 的,Gearpump 是 Intel 的,Edgent 是 IBM 的,三巨头提前对流计算做出了布局。Gearpump 是以 Akka 为核心的分布式轻量级流计算,Akka stream 和 Akka http 模块享誉技术圈。Spark 早期的分布式消息传递用 Akka,Flink 一直用 Akka 做模块间消息传递。Akka 类似 erlang,采用 Actor 模型,对线程池充分利用,响应式、高性能、弹性、消息驱动的设,CPU 跑满也能响应请求且不死,可以说是高性能计算中的奇葩战斗机。Gearpum 自从主力离职后项目进展不大,且在低功耗的 IoT 场景里没有好的表现,又干不过 Flink 和 Spark。Edgent 是为 IoT 而生的,内嵌在网关或边缘设备上,实时分析流数据,目前还在 ASF 孵化中。物联网和边缘计算要依托 Top 级的云厂商才能风生水起,而各大厂商都有 IoT 主力平台,仅靠 Edgent 似乎拼不过。
Kafka Stream: Kafka 是大数据消息队列标配,基于 log append-only,得益于零拷贝,Kafka 成为大数据场景做高吞吐的发布订阅消息队列首选。如今,不甘寂寞的 Kafka 也干起了流计算,要处理简单的流计算场景,Kafka SQL 是够用的。但计算和存储分离是行业共识,资源受限的边缘计算场景需要考虑计算存储一体化。重量级的 Kafka 在存储的同时支持流分析,有点大包大揽。第一,存储计算界限不明确,都在 Kafka 内;第二,Kafka 架构陈旧笨重,与基于 DistributedLog 的流存储体系相比仍有差距;计算上又不如 Pulsar 等轻量。Kafka Stream SQL 轮子大法跟 Flink SQL 和 Spark SQL 有不小差距。个人感觉,危机大于机遇。
实时流计算技术的进一步发展,需要 IoT、工业 IoT、智慧 xx 系列、车联网等新型行业场景催生,同时背靠大树才好活。
后来者 Flink
Flink 到 16 年才开始崭露头角,不得不八卦一下其发家史。
Stratosphere项目最早在 2010 年 12 月由德国柏林理工大学教授 Volker Markl 发起,主要开发人员包括 Stephan Ewen、Fabian Hueske。Stratosphere 是以 MapReduce 为超越目标的系统,同时期有加州大学伯克利 AMP 实验室的 Spark。相对于 Spark,Stratosphere 是个彻底失败的项目。所以 Volker Markl 教授参考了谷歌的流计算最新论文 MillWheel,决定以流计算为基础,开发一个流批结合的分布式流计算引擎 Flink。Flink 于 2014 年 3 月进入 Apache 孵化器并于 2014 年 11 月毕业成为 Apache 顶级项目。
流批合一,是以流为基础,批是流的特例或上层 API;批流合一,是以批计算为基础,微批为特例,粘合模拟流计算。
Spark vs. Flink
丑话说在前面,笔者无意于撩拨 Flink 和 Spark 两个群体的矛盾,社区间取长补短也好,互相抄袭也好,都不是个事,关键在于用户群体的收益。
在各种会上,经常会被问到 Spark 和 Flink 的区别,如何取舍?
下面从数据模型、运行时架构、调度、时延和吞吐、反压、状态存储、SQL 扩展性、生态、适用场景等方面来逐一分析。
数据模型
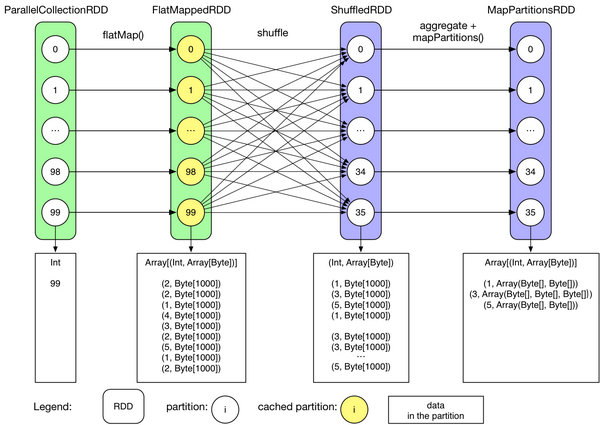
Spark RDD 关系图。图片来自 JerryLead 的 SparkInternals 项目
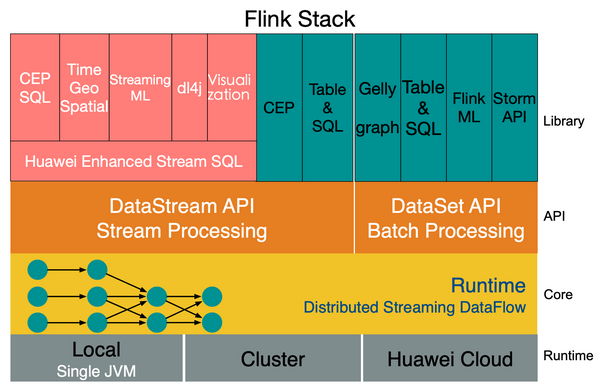
Flink 框架图

Flink 运行时
Spark 的数据模型
Spark 最早采用 RDD 模型,达到比 MapReduce 计算快 100 倍的显著优势,对 Hadoop 生态大幅升级换代。RDD 弹性数据集是分割为固定大小的批数据,RDD 提供了丰富的底层 API 对数据集做操作。为持续降低使用门槛,Spark 社区开始开发高阶 API:DataFrame/DataSet,Spark SQL 作为统一的 API,掩盖了底层,同时针对性地做 SQL 逻辑优化和物理优化,非堆存储优化也大幅提升了性能。
Spark Streaming 里的 DStream 和 RDD 模型类似,把一个实时进来的无限数据分割为一个个小批数据集合 DStream,定时器定时通知处理系统去处理这些微批数据。劣势非常明显,API 少、难胜任复杂的流计算业务,调大吞吐量而不触发背压是个体力活。不支持乱序处理,把前面的 Kafka topic 设置为 1 个分区,鸡贼式缓解乱序问题。Spark Streaming 仅适合简单的流处理,会被 Structured Streaming 完全替代。
Spark Structured Streaming 提供了微批和流式两个处理引擎。微批的 API 虽不如 Flink 丰富,窗口、消息时间、trigger、watermarker、流表 join、流流 join 这些常用的能力都具备了。时延仍然保持最小 100 毫秒。当前处在试验阶段的流式引擎,提供了 1 毫秒的时延,但不能保证 exactly-once 语义,支持 at-least-once 语义。同时,微批作业打了快照,作业改为流式模式重启作业是不兼容的。这一点不如 Flink 做的完美。
综上,Spark Streaming 和 Structured Streaming 是用批计算的思路做流计算。其实,用流计算的思路开发批计算才是最优雅的。对 Spark 来讲,大换血不大可能,只有局部优化。其实,Spark 里 core、streaming、structured streaming、graphx 四个模块,是四种实现思路,通过上层 SQL 统一显得不纯粹和谐。
Flink 的数据模型
Flink 采用 Dataflow 模型,和 Lambda 模式不同。Dataflow 是纯粹的节点组成的一个图,图中的节点可以执行批计算,也可以是流计算,也可以是机器学习算法,流数据在节点之间流动,被节点上的处理函数实时 apply 处理,节点之间是用 netty 连接起来,两个 netty 之间 keepalive,网络 buffer 是自然反压的关键。经过逻辑优化和物理优化,Dataflow 的逻辑关系和运行时的物理拓扑相差不大。这是纯粹的流式设计,时延和吞吐理论上是最优的。
Flink 在流批计算上没有包袱,一开始就走在对的路上。
运行时架构
Spark 运行时架构
批计算是把 DAG 划分为不同 stage,DAG 节点之间有血缘关系,在运行期间一个 stage 的 task 任务列表执行完毕,销毁再去执行下一个 stage;Spark Streaming 则是对持续流入的数据划分一个批次,定时去执行批次的数据运算。Structured Streaming 将无限输入流保存在状态存储中,对流数据做微批或实时的计算,跟 Dataflow 模型比较像。
Flink 运行时架构
Flink 有统一的 runtime,在此之上可以是 Batch API、Stream API、ML、Graph、CEP 等,DAG 中的节点上执行上述模块的功能函数,DAG 会一步步转化成 ExecutionGraph,即物理可执行的图,最终交给调度系统。节点中的逻辑在资源池中的 task 上被 apply 执行,task 和 Spark 中的 task 类似,都对应线程池中的一个线程。
在流计算的运行时架构方面,Flink 明显更为统一且优雅一些。
时延和吞吐
两家测试的 Yahoo benchmark,各说各好。benchmark 鸡肋不可信,笔者测试的结果,Flink 和 Spark 的吞吐和时延都比较接近。
反压
Flink 中,下游的算子消费流入到网络 buffer 的数据,如果下游算子处理能力不够,则阻塞网络 buffer,这样也就写不进数据,那么上游算子发现无法写入,则逐级把压力向上传递,直到数据源,这种自然反压的方式非常合理。Spark Streaming 是设置反压的吞吐量,到达阈值就开始限流,从批计算上来看是合理的。
状态存储
Flink 提供文件、内存、RocksDB 三种状态存储,可以对运行中的状态数据异步持久化。打快照的机制是给 source 节点的下一个节点发一条特殊的 savepoint 或 checkpoint 消息,这条消息在每个算子之间流动,通过协调者机制对齐多个并行度的算子中的状态数据,把状态数据异步持久化。
Flink 打快照的方式,是笔者见过最为优雅的一个。Flink 支持局部恢复快照,作业快照数据保存后,修改作业,DAG 变化,启动作业恢复快照,新作业中未变化的算子的状态仍旧可以恢复。而且 Flink 也支持增量快照,面对内存超大状态数据,增量无疑能降低网络和磁盘开销。
Spark 的快照 API 是 RDD 基础能力,定时开启快照后,会对同一时刻整个内存数据持久化。Spark 一般面向大数据集计算,内存数据较大,快照不宜太频繁,会增加集群计算量。
SQL 扩展性
Flink 要依赖 Apache Calcite 项目的 Stream SQL API,而 Spark 则完全掌握在自己手里,性能优化做的更足。大数据领域有一个共识:SQL 是一等公民,SQL 是用户界面。SQL 的逻辑优化和物理优化,如 Cost based optimizer 可以在下层充分优化。UDX 在 SQL 之上可以支持在线机器学习 StreamingML、流式图计算、流式规则引擎等。由于 SQL 遍地,很难有一个统一的 SQL 引擎适配所有框架,一个个 SQL-like 烟囱同样增加使用者的学习成本。
生态和适用场景
这两个方面 Spark 更有优势。
Spark 在各大厂实践多年,跟 HBase、Kafka、AWS OBS 磨合多年,已经成为大数据计算框架的事实标准,但也有来自 TensorFlow 的压力。14 年在生产环境上跑机器学习算法,大多会选择 Spark,当时我们团队还提了个 ParameterServer 的 PR,社区跟进慢也就放弃了。社区为赶造 SQL,错过了 AI 最佳切入时机。这两年 Spark+AI 势头正劲,Matei 教授的论文 Weld 想通过 monad 把批、流、图、ML、TensorFlow 等多个系统粘合起来,统一底层优化,想法很赞;处于 beta 阶段的 MLFlow 项目,把 ML 的生命周期全部管理起来,这些都是 Spark 新的突破点。
反观 Flink 社区,对周边的大数据存储框架支持较好,但在 FlinkML 和 Gelly 图计算方面投入极匮乏,16 年给社区提 PS 和流式机器学习,没一点进展。笔者在华为云这两年多时间,选择了 Flink 作为流计算平台核心,索性在 Flink 基础之上开发了 StreamingML、Streaming Time GeoSpatial、CEP SQL 这些高级特性,等社区搞,黄花菜都凉了。
企业和开发者对大数据 AI 框架的选择,是很重的技术投资,选错了损失会很大。不仅要看框架本身,还要看背后的公司。
Spark 后面是 Databricks,Databricks 背靠伯克利分校,Matei、Reynold Xin、孟祥瑞等高手如云。Databricks Platform 选择 Azure,14 年 DB 就用改造 notebook 所见即所得的大数据开发平台,前瞻性强,同时对 AWS 又有很好的支持。商业和技术上都是无可挑剔的。
Flink 后面是 DataArtisans,今年也推出了 data Artisans Platform,笔者感觉没太大新意,对公有云私有云没有很好的支持。DataArtisans 是德国公司,团队二三十人,勤勉活跃在 Flink 社区,商业上或许势力不足。
开源项目后面的商业公司若不在,项目本身必然走向灭亡,纯粹靠分散的发烧友的力量无法支撑一个成功的开源项目。Databricks 估值 1.4 亿美元,DataArtisans 估值 600 万美元,23 倍的差距。DataArtisans 的风险在于变现能力,因为盘子小所以有很大风险被端盘子,好在 Flink 有个好的 Dataflow 底子。这也是每个开源项目的难题,既要商业支撑开销,又要中立发展。
对比小结
啰嗦这么多,对比下 Flink 和 Spark:
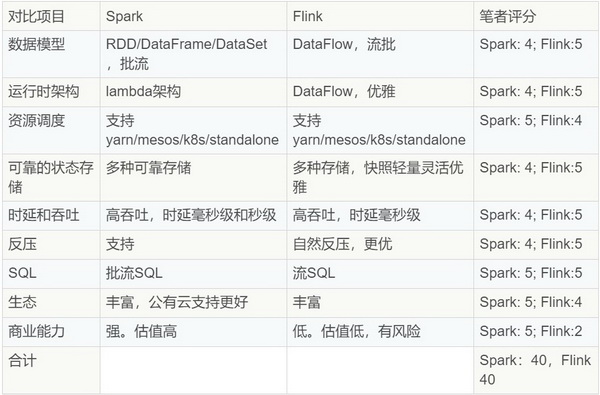
Flink 和 Spark 在流计算方面各有优缺点,分值等同。Flink 在流批计算方面已经成熟,Spark 还有很大提升空间,此消彼长,未来不好说。
边缘计算的机会
边缘计算近两年概念正盛,其中依靠的大数据能力主要是流计算。公有云、私有云、混合云这么成熟,为何会冒出来个边缘计算?
IoT 技术快速成熟,赋能了车联网、工业、智慧城市、O2O 等线下场景。线下数据高速增长,敏感数据不上云,数据量太大无法上云,毫秒级以下的时延,这些需求催生了靠近业务的边缘计算。在资源受限的硬件设备上,业务数据流实时产生,需要实时处理流数据,一般可以用 lambda 跑脚本,实时大数据可以运行 Flink。华为云已商用的 IEF 边缘计算服务,在边缘侧跑的就是 Flink lite,Azure 的流计算也支持流作业下发到边缘设备上运行。
边缘设备上不仅可以运行脚本和 Flink,也可以执行机器学习和深度学习算法推理。视频摄像头随处可见,4K 高清摄像头也越来越普遍,交警蜀黎的罚单开的越来越省心。视频流如果全部实时上传到数据中心,成本不划算,如果这些视频流数据能在摄像头上或摄像头周边完成人脸识别、物体识别、车牌识别、物体移动侦测、漂浮物检测、抛洒物检测等,然后把视频片段和检测结果上传,将极大节省流量。这就催生了低功耗 AI 芯片如昇腾 310、各种智能摄像头和边缘盒子。
Flink 这类能敏捷瘦身且能力不减的流计算框架,正适合在低功耗边缘盒子上大展身手。可以跑一些 CEP 规则引擎、在线机器学习 Streaming、实时异常检测、实时预测性维护、ETL 数据清洗、实时告警等。
行业应用场景
实时流计算常见的应用场景有:日志分析、物联网、NB-IoT、智慧城市、智慧工厂、车联网、公路货运、高速公路监测、铁路、客运、梯联网、智能家居、ADAS 高级辅助驾驶、共享单车、打车、外卖、广告推荐、电商搜索推荐、股票交易市场、金融实时智能反欺诈等。只要实时产生数据、实时分析数据能产生价值,那么就可以用实时流计算技术,单纯地写一写脚本和开发应用程序,已经无法满足这些复杂的场景需求。
数据计算越实时越有价值,Hadoop 造就的批计算价值已被榨干。在线机器学习、在线图计算、在线深度学习、在线自动学习、在线迁移学习等都有实时流计算的影子。对于离线学习和离线分析应用场景,都可以问一下,如果是实时的,是否能产生更大价值?
去新白鹿用二维码点餐,会享受到快速上菜和在线结账;叫个外卖打个车,要是等十分钟没反应,必须要取消订单。互联网催化各个行业,实时计算是其中潮头,已渗透在生活、生产、环境的方方面面。
对比各家云厂商的流计算服务
不重复造轮子已成业界共识。使用公有云上 serverless 大数据 AI 服务(全托管、按需收费、免运维),会成为新的行业共识。高增长的企业构筑大数据 AI 基础设施需要较高代价且周期不短,长期维护成本也高。
企业上云主要担心三个问题:
♦ 数据安全,数据属于企业核心资产;
♦ 被厂商锁定;
♦ 削弱自身技术能力。
对于数据安全,国内的《网络安全法》已经正式实施,对个人隐私数据保护有法可依;另外欧盟 GDPR《通用数据保护条例(General Data Protection Regulation)》正式生效,都说明法律要管控数据乱象了。
选择中立的云厂商很关键。云厂商大都会选择开源系统作为云服务的基石,如果担心被锁定,用户选择云服务的时候留意下内核就好。当然,这会导致开源社区和云厂商的矛盾,提供企业化大数据平台可能会被公有云抢生意,开源社区要活下去,DataBricks 跟 Azure 的合作例子就是聪明的选择。
担心削弱公司技术能力,倒是不必。未来大数据框架会越来越傻瓜化,运维和使用门槛也会越来越低,企业不如把主要精力聚焦于用大数据创造价值上,不为了玩数据而玩数据,是为了 make more money。
目前常见的流计算服务包括:
♦ AWS Kinesis
♦ Azure 流分析
♦ Huawei Cloud 实时流计算服务
♦ Aliyun 实时计算
AWS Kinesis 流计算服务推出较早,目前已经比较成熟,提供 serverless 能力,按需收费、全托管、动态扩容缩容,是 AWS 比较赚钱的产品。Kinesis 包含 Data Streams、Data Analytics、Data Firehose、Video Streams 四个部分。Data Streams 做数据接入,Data Firehose 做数据加载和转储,Data Analytics 做实时流数据分析,Video Streams 用于流媒体的接入、编解码和持久化等。Azure 的流分析做的也不错,主打 IoT 和边缘计算场景。从 Kinesis 和 Azure 流分析能看出,IoT 是流分析的主战场。产品虽好,国内用的不多,数据中心有限而且贵。
华为云实时流计算服务是以 Flink 和 Spark 为核心的 serverless 流计算服务,早在 2012 年华为就开始了自研的 StreamSmart 产品,广泛在海外交付。由于生态闭源,团队放弃了 StreamSmart,转投 Flink 和 Spark 双引擎。提供 StreamSQL 为主的产品特性:CEP SQL、StreamingML、Time GeoSpartial 时间地理位置分析、实时可视化等高级特性。首创独享集群模式,提供用户间物理隔离,即使是两个竞争对手也可以同时使用实时流计算服务,用户之间物理隔离也断绝了用户间突破沙箱的小心思。
阿里云的流计算服务,最早是基于 Storm 的 galaxy 系统,同样是基于 StreamSQL,产品早年不温不火。自从去年流计算彻底转变,内核改为 Flink,经过双 11 的流量检验,目前较为活跃。
总结 & 展望
实时流计算技术已经成熟,大家可以放心使用。目前的问题在于应用场景推广,提升企业对云厂商的信任度,广泛应用流计算创造价值。而流计算与 AI 的结合,也会是未来可能的方向:
StreamingML 在线机器学习
StreamingGraph 在线图计算
StreamingAI 实时 AI
流批合一
流存储
实时流计算 + 边缘计算、工业 IoT、车联网、智慧城市
作者介绍
时金魁,华为云高级技术专家,负责华为云实时流计算服务。多年来从事高性能计算和大数据方面的工作,近两年专注于 Flink 和 Spark 及周边生态框架的研究和产品落地。曾就职于搜狐、淘宝和阿里云。标准的 Scala 程序员。

时间:2018-12-18 23:37 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















