谷歌中国工程师提出颠覆性算法模型,Waymo实测可提高预测精准度
“周围的车辆和行人在接下来数秒中会做什么?”要实现安全的自动驾驶,这是一个必须回答的关键问题,这也就是自动驾驶领域中的行为预测问题。
自动驾驶公司 Chris Urmson 去年曾在一次采访中表示,感知和预测能力很关键,如果有一个模型能预测未来 5 秒会发生什么,这将能很大程度加速自动驾驶的发展。
行为预测的难点在于周围行人、车辆的不确定性和各种规则之外的行为。这些状况难以进行确定性的预测,只能通过训练数据分析各种行为的可能性来达到更加合理的预测效果。另一个难点是盲区与遮挡问题。
面对这种情况时,人类司机通常会基于自己的驾驶经验对周围信息产生一个预期。这种经验之举显示出,行为预测的基础在于对环境的认识和理解。
在这一方面,来自 Waymo 和谷歌的一个中国工程师团队提出了一个全新模型 VectorNet。
在该模型中,团队首次提出了一种抽象化认识周围环境信息的做法:用向量(Vector)来简化地表达地图信息和移动物体,这一做法抛开了传统的用图片渲染的方式,达到了降低数据量、计算量的效果。
在向量化的基础上,该模型在所有向量之间添加了语义关系,让机器(自动驾驶车辆)不仅能看到环境信息,更能进一步理解环境中不同要素之间的关系。在自动驾驶的语境下,对要素之间关系的认识可以帮助进行行为预测。
在实际测试当中,该模型的行为预测精准度比现有方法提升了近 20%,而在占用内存和计算量上则减少了约 8 成。
目前该论文已经被计算机视觉领域三大国际顶会之一的 CVPR 接收,Waymo 也在其博客文章中明确表示该技术提高了其行为预测的精准度。
抽象地 “认识” 世界
正如 Waymo 在博客中指出,该研究的突破性意义在于首次提出了用向量的方式来抽象化表达这个世界。
以无人车为例,周围的环境信息可以大致分为两类。一是地图特征,其中包括车道线、斑马线、红绿灯、速度标示、停车指示牌等等固有的道路要素;第二大类,就是无人车周围的物体运动轨迹。
VectorNet 论文中提到,在用向量表达的方法中,向量本身可以被输入多方面的信息。其中包括:1、向量的起点位置;2、向量的终点位置;3、向量对应的道路要素,比如这是条车道线、红路灯等;4、向量对应要素的属性,比如限速标示要求的速度大小、红绿灯会指示车辆的前行和停下等。

4 种信息对应了不同的信息和功能,当这些信息集合,工程师能通过这种向量的方式让整个周围环境抽象化成了诸多向量的组合,实现了在机器内对周围环境的捕捉和重建。
据了解,要表达周围环境的信息和物体,此前业界的广泛做法是将车道线等地图信息和车辆等运动物体渲染(render)到栅格图(Raster graphics)上,再通过卷积神经网络(CNN)进行建模,进而实现后续的行为预测等操作。
但弊端在于,将物体渲染到图片上是一个非常消耗算力的过程。且原本机器只是需要表达周围的少量物体,本身的数据量是很小的,但在渲染成为一张图片之后,数据量就显著上升。
因此可以说,传统上将物体渲染到图片上的做法从时间和空间上来看,是一个缺乏效率的方式。
此外,卷积神经网络在自动驾驶行为预测方面有着根本的局限性。由于行为预测通常需要捕获长距离道路的几何特征,但卷积神经网络却并不适合应对长距离的道路信息。
卷积神经网络依靠 3×3、5×5 这样的卷积核(kernel)进行计算,意味着这种方式能够很好捕捉局部的环境信息,但像车道线这样长条的环境信息常常会贯穿整张图片,因此小的卷积核就没有足够的感受野(receptive field)能够捕捉整条车道线的几何特征。
论文提到,卷积感受野对预测质量至关重要,测试表明更大的卷积核带来感受野的提升能够改善无人车行为预测的结果,但代价同样巨大:计算成本会进一步提升。
在 VectorNet 模型的做法下,无需将环境信息渲染成图片,而表达成抽象、简化的向量形式,如此一来,模型和数据量都大幅减少,模型的计算速度可以比卷积神经网络快上一个数量级。
因此 VectorNet 在实际应用中具备很强的实用性,可以提升 Waymo 自动驾驶测试的行为预测精准度。
一位业内人士表示“我觉得过去学术界更多的工作都放在了预测模型上,但这些工作都忽略了一个基本问题——现在的输入表征还没做好。现在大家都是通过渲染 + 卷积神经网络的方式去做输入表征,再基于此去做不同的预测模型进行轨迹预测。这就导致了,当输入表征本身还存在很大问题的情况下,预测模型的设计也很难说是有效的。”
这一说法也强调了,该模型的最大贡献是提出了一个 “如何表示地图、如何用神经网络去学习地图内容” 的新模式。
让机器 “理解” 世界
抽象化表达世界只是 VectorNet 模型的第一步,在有了向量图之后,理解不同要素之间的联系,学习要素之间的语义信息成了更可行的一步,最终才能让机器学实现从 “看到世界” 到“理解世界”的发展。
在此之前,卷积神经网络擅长于编码位置关系,但在学习多个要素之间的连接关系面前则显得吃力。
相比之下,图神经网络(Graph Neural Network)注重连接关系,而非注重空间位置关系。在一个网状结构里,普通的图神经网络非常善于将线和节点之间的语义关系学习出来,但却无法学习节点之间的位置关系,这也是图神经网络最大的问题。
对自动驾驶依靠的地图信息来说,周围要素之间的位置信息和语义信息都很重要。一方面要精准表达车辆、车道线、红绿灯等要素的位置信息;与此同时,在复杂的交通场景中,车辆等物体的运动状态受到多种要素的综合影响,比如红绿灯、道路交规的指示,周围物体的运动也会影响车辆的行进决策,这即是要素之间的语义关系。
要更好地对周围车辆进行行为预测,理解其中的语义信息就显得至关重要。
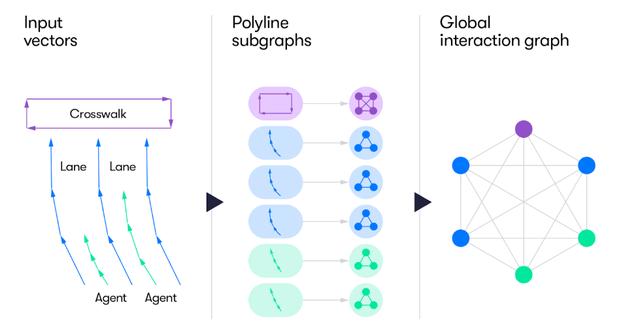
在用向量表达周围信息的基础之上,团队提出了分层图形神经网络(hierarchical graph neural network ),在所有向量之间建立语义联系,从而在模型中同时放入了地图上所有要素的位置信息和要素之间的语义信息。
这么做相当于在前期人为告诉模型:周围的所有要素都可能影响车辆的运动行为决策。而在后续的学习当中,模型能够自动学习到在诸多要素当中,哪些要素会对车辆行进产生影响,以及不同要素之间的影响程度。
根据 Waymo 在博客中介绍,相比目前广泛使用的 ResNet , VectorNet 在预测的精准度上提高了 18%,更重要的是,它在进行行为预测时占用的内存仅为 ResNet 的 29%,计算量也仅为后者的 20%。

图 | 测试结果对比
此外,对周围环境理解的加深也能让机器在学习中获得类似人类司机的经验,学习不同要素之间的语义关系能对周围可能发生的情况作出推断。比如当路边的停车标志被意外遮挡时,人类驾驶员可以根据过往的经验推测标志的内容,在对 VectorNet 的训练中,随机遮挡部分地图特征能够进一步提升 VectorNet 的预测能力,根据此前的学习经验可以更好推测缺失的地图信息,最终在必要时及时作出应对。
事实上,在后续训练中 VectorNet 已经通过学习形成了一套“注意力机制”,论文给出的例子显示,当自动驾驶车辆行进、变道的过程当中,机器已经自己认识到当前车道和目标车道上的信息是更加需要关注的。这显示出了该模型对周围环境信息产生了进一步的“理解”,这一现象也反过来表明了该模型的可解释性。

图 | 论文作者团队,左至右分别为赵行、孙晨、高继扬
论文作者团队来自谷歌和 Waymo。其中,高继扬目前是 Waymo 的高级软件工程师,本科毕业于清华大学,2018 年在美国南加州大学获电机工程博士学位;赵行本科毕业于浙江大学,之后在麻省理工学院拿到硕士、博士学位,目前在 Waymo 担任研究员;孙晨本科同样就读于清华大学,后于 2015 年博士毕业于南加州大学,目前在谷歌任研究员。

时间:2020-05-21 23:03 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [智能驾驶]丰田,博世,戴姆勒押注中国无人驾驶的未来,加入了Momenta的5亿美元融资
- [智能驾驶]TuSimple的IPO档案揭示了具有中国纽带的自动驾驶初创企业的障碍
- [智能驾驶]小鹏P7迎重大OTA升级 NGP适合中国路况-泷本梨绘
- [智能驾驶]路透社:特朗普签令评估中国无人机对美的“安
- [智能驾驶]中国首次运用北斗技术实现集装箱码头自动化
- [智能驾驶]圆满!嫦娥五号完成中国首次月球采样返回任务
- [智能驾驶]嫦娥五号成功降落内蒙古 中国航天局:已运回
- [智能驾驶]中国成功发射“引力波暴高能电磁对应体全天监
- [智能驾驶]AutoX“真无人”车队驶上繁忙街头,中国正式跨入
- [智能驾驶]嫦娥五号发射成功!中国将首次在地外天体采样
相关推荐:
网友评论:















