妇产科知识图谱构建研究与实现
目前医学领域知识图谱基本都是较小规模,限定到细分领域。尝试以妇产科教材为基础,利用自然语言处理技术对医学知识进行系统的梳理、建模和展示,快速构建出妇产科领域知识图谱,并采用Neo4j图数据库将知识进行可视化展示,以图的形式凸显各类概念间的关系。该知识图谱既能帮助医学专家理清知识脉络,又能发现各知识点的联系,也能帮助非专业人士快速了解医学类常识。
国内外最有影响力的知识图谱现状
知识图谱通常定义为海量实体与实体关系的集合。国内外最有影响力的知识图谱工程包括以下几种。
Freebase/谷歌知识图谱。Freebase是个类似于维基百科的创作共享类网站,所有内容通过协作的方式由用户添加。
YAGO(Yet Another Great Ontology)系列知识图谱[3]。YAGO由德国Max Planck计算机科学研究所创建。YAGO通过对维基百科和其它来源的自动挖掘而构建。目前YAGO已经完成了三个版本的知识图谱。
微软的Satori[4]和Facebook的Entity Graph。微软的Satori与谷歌知识图谱类似而Entity Graph主要以Facebook自身的数据为主,服务于Facebook的图搜索(Graph Search)。
NELL(Never-Ending Language Learning)由卡内基-梅隆大学的Tom Mitchell教授领导的团队构建。目标是从非结构化文本中自动地学习实体和实体关系。与NELL类似的一个项目是Open Information Extraction (Reverb,OLLIE),同样从非结构化文本中自动抽取关系。
国内的知识图谱建设起步较晚,主要集中在互联网公司。搜狗知立方是国内首款知识库搜索产品。百度知心是百度下一代搜索引擎的雏形,目前具有数十亿级实体规模。
知识图谱被应用到各大领域,如医疗健康、金融、电商、出版、农业、政府、电信、数字图书馆等等。在电商领域,唐伟等抽取商品的知识图谱。在医疗健康领域,目前有中国医学院医学信息研究所构建的约11种疾病的知识图谱。Google构建了包含常见症状、治疗手段、受此问题影响的典型年龄组、是否严重等信息的知识图谱。中国中医科学院中医药信息研究所主要以中医药学语言系统为知识图谱的骨架构建中医药知识图谱体系。
妇产科知识图谱构建流程及技术
选用《妇产科学第七版》作为处理的教材。其内容可靠、表述规范。构建流程包括数据清洗及数据格式预处理、疾病实体抽取、症状实体抽取、实体关系识别等四个模块。
数据清洗及格式预处理 由于教材电子版为自由文本,需对这些数据进行清洗。包括格式解析、大小写字母转换、全角半角转换、繁体转简体等,因后续方法均在句子级进行操作,因此本模块还需对文本进行分句,共得到12 098个句子。
疾病实体抽取技术 根据知识图谱的定义,知识图谱由实体与实体间的关系组成。因此实体库是知识图谱的基础内容。建设一个实体库通常分为以下几个步骤,包括确定实体类别体系、实体的挖掘。
实体类别体系通常根据不同的用途进行人工构建。分析医学教材的特点,发现教材的附录和目录中包含大量的疾病实体,因此先采用规则的方式,获取本教材中的疾病实体。经过收集整理,得到初步的疾病实体库。
症状实体抽取技术 医学教材中,症状分布比较分散。根据分析教材书写方式,选用步步为营的算法来扩充症状实体的规模。人工给定一些症状实体作为种子,在包含这些种子的文本中获取抽取模板,做模板筛选之后利用新的模板集合获取更多的实体。这个过程中进行多次迭代从而获得实体集合。算法描述如表1所示。自动挖掘得到的实体存在噪音,需要经过人工校对才可以放入到实体库中。

实体关系挖掘技术 关系抽取是指确定实体之间的关系。目前常用的实体关系可以表示为RDF三元组,即<实体A,实体B,关系>。以初始知识库中的出现的关系为抽取目标,把所有的概念都看成是实体,所有实体间的语义关联都描述为实体间的关系。目前关系包括疾病与疾病、疾病与症状、疾病和治疗手段等的关系,根据这些关系再进行扩充,构建出医学领域的关系体系。比如,在疾病的症状关系类型中,分析数据发现,句子中有明显得关系指示词,“症状是”,“等症状”,“表现为等”。因此关系抽取算法中,首先专家定义关系抽取模板,在数据中自动标注关系,然后再挖掘出新的模板,不断迭代,将不同的关系抽取出来。
自动挖掘的实体和关系难以避免包含错误。在将自动挖掘实体归并到实体库之前,需要进行校对和筛选。采用人工校对方式,由领域专家进行校验。
知识图谱存储
为了表示实体关系,知识图谱通常采用图形数据库(Graph Database)而不是基于表的知识库进行存储。选择存储体系时需要考虑潜在的数据规模、可能的应用模式等因素。特定领域的知识图谱与通用知识图谱相比规模相对有限,因此采用Neo4j作为底层的存储体系。Neo4j是以Java实现的开源图形数据库,遵循AGPL v3协议。经上述技术,共得到528条知识。部分知识图谱如图1所示。
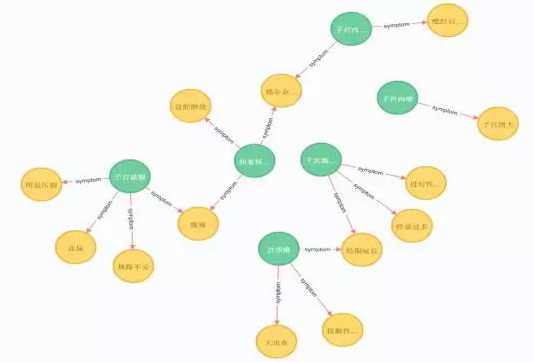
图1 妇产科知识图谱示例
结语
阐述了妇产科知识图谱的构建与存储。初步构建并可视化了医学方面的知识图谱。目前处理的数据来源较少,也未能与其他细分领域医学知识联系起来。如何构建全医学领域的知识图谱是一项具有挑战的任务。相信随着机器学习以及自然语言处理技术的成熟,对文本类型的数据处理更加准确。知识图谱将在医疗健康领域起到重要的作用。

时间:2019-03-05 18:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














