AI的多任务处理能力已经超越人类
过去十几年,人类可以说是在机器智能面前节节退败,屡败屡战。而多任务处理(multi-tasking),几乎是为数不多可以让我们“天生骄傲”的能力了。
比如,人可以同时打开8个网站、3份文档和一个Facebook,即使正在专心处理其中一件事,只要突然收到一条回复或更新提醒,也能够快速安排的明明白白。

对机器而言,要在同一时间完成这样的任务显然有点难。因此,多任务处理一直被视作是人类所独有的的技能点。
然而,这个优势似乎也快要失守了。
Deepmind一项最新的研究成果显示,借助其开发的PopArt方法来训练深度学习引擎,能够培养出可进行多任务处理的智能体,并且在实际的表现中超越了人类!
让机器“一心多用”的PopArt,究竟是如何工作的?
关于多任务学习的研究已经持续了大概20年之久,尽管一直没能像单任务学习(如AlphaGo)那样做出什么夺人眼球的成果,但显然更符合我们对“机器模拟人脑”的想象。
毕竟在现实生活中,各种“学习任务”之间都有着千丝万缕的联系,比如当人在玩电子游戏时,图像识别、任务理解、执行操作并追求收益最大化,这些都可以在瞬间完成的操作,并且在任何一个游戏中都可以如法炮制,而机器目前只能通过分解成单个任务去学习并处理。
怎样指导机器在同一时间完成多个复杂任务,Deepmind提出了一个新的方法“PopArt”,据说可以让机器在多任务处理上的成绩超越人类。
如名字所示,PopArt(Preserving Outputs Precisely while AdapTIvely Rescaling Targets),即在自适应重新缩放目标的同时精确保留原有输出。
有人可能会说,这句话里每个汉字我都认识,但凑在一起竟然完全不知道说的是啥?
不要方,我们今天就来“庖丁解牛”,告诉大家这个能够让机器“一心多用”的PopArt,究竟是何方神圣?
简单来说,PopArt的工作机制就是在机器对不同任务的学习数据进行加权之前,先对数据目标进行自动的“归一化”调整,再将其转换成原始数据输出给机器。
这一做法有两个好处:
一是让机器对不同奖励大小和频率的多个任务进行更稳健、一致的学习。
对于机器而言,多任务学习比单一任务学习更困难的最主要原因就是,多任务学习必须要将有限的资源分配给多个任务目标,但常规算法对不同任务设置的权重也有所不同。这就导致机器智能体会根据任务回报的多寡来选择执行哪些任务。
举个例子,同样是A游戏,机器在处理《pong》(一款乒乓球游戏)时只能得到-1、0或+1的奖励,而处理《吃豆人小姐》游戏时,则可以获得上千个积分,机器自然会更专注于执行后者。
即使开发者将单个奖励设置成一样的,随着不同游戏奖励频率的不同,差距还是会越来越大,依然会影响机器的判断。
结果就是,这个智能体会在处理某些任务上表现越来越好,但在其他任务上却越来越力不从心。
但PopArt可以很好地解决这个机器“偏心”的问题。
DeepMind将PopArt应用在自己最常用的深度强化学习智能体IMPALA上,让它同时处理57个Atari经典游戏,结果令人震惊——
应用了PopArt的IMPALA,不仅分数远远高于原始IMPALA的表现,甚至超越了人类的成绩!
下图中可以看到,修正游戏数据权重后的IMPALA(蓝色)性能表现接近于0%,与PopArt-IMPALA中位数101%的华丽数据形成了鲜明对比。
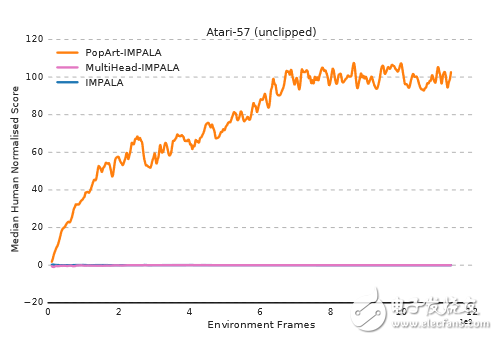
简单来说,就是PopArt自适应调整了每个游戏中奖励分支的大小,让机器认为不同任务带给自己的奖励是相同的,拥有同等的学习价值,因此,尽管这57个游戏有着巨量的环境、不一样的动态和完全不同的奖励机制,但机器都能够对它们“一视同仁”。
据我们所知,这还是当前单个智能体首次超越人类在多任务处理上的表现。
PopArt的第二重作用,则是能够有效增加机器学习智能体的数据效率,降低训练成本。
Deepmind发现,PopArt-IMPALA与像素控制技术相结合,只需要不到十分之一的数据量,就能达到原来的训练效果,这使其数据效率大幅提升。
因此,PopArt-IMPALA在大型多任务训练任务中,不仅比专家智能体DQN性能更高,而且更加便宜。
如果将训练任务放到云端,PopArt-IMPALA的性能只用了2.5天就超过了DQN,GPU占用空间更小,直接促使训练成本大幅降低。
Deepmind和OpenAI,技术大佬为何都对“多任务学习”情有独钟?
除了PopArt,今年早期,Deepmind还提出了另一种用于多任务训练的新方法——Distral,通过捕捉不同任务之间的共同行为或特征,让机器算法可以在被限制的条件下实现任务共享,从而进行同步强化学习。
和Deepmind一样跟“多任务学习”死磕的还有OpenAI,则是利用迭代扩增方法,不给机器学习模型提供完整的标注数据,而是将每一项任务分解成小的子任务,再为子任务提供训练信号,训练AI去完成复杂任务。
此外,MIT、Apple等顶尖技术玩家都在捣鼓这项技术,然而如果你把这当做一个技术领域的“荣誉保卫战”或者论文制造机,那就大错特错了。
随着AI的泛在化越来越强,有越来越多的领域都亟待“多任务学习”能力来提供新的解决方案。
这意味着,人类不需要针对每一项任务都从头开始训练一个全新的智能体,而是可以构建一个通用的智能体,来支持多个应用之间的协同工作。
比如小到一台电视,很多AI电视都整合了众多功能,比如观看视频、天气预报、事务提醒、网络购物等等,如何在既不影响用户看视频,又能够用语音唤醒其他功能?这就要依靠多任务并行处理。换句话说,不具备多任务学习能力的AI电视,有的只是一个“假脑子”。
大到一个城市。在众多关于智慧城市的假想中,都少不了这样一个场面:城市大脑将人、车、路数据都接入系统,生成一个交通实时大试图,并以此完成交通系统的智能调度和管理,治疗“交通病”。这意味着,城市大脑需要进行摄像头识别、城市空间布局和设施配置、事件预警、政务服务等多个系统的学习,能够发掘出这些子系统之间的关系,又能区分这些任务之间的差别。缺了任何一环,都有可能导致这个城市大脑做出“奇葩”的决策。
当然,对于研究者来说,在用每一点进步无限逼近人类心智的“珠穆朗玛峰”。但对产业而言,任何新技术的落地都从来容不得一丝任性,因为每一颗种子都在等待丰收。
为了满足这个前提,就意味着所采取的方法不能以无限制地增加GPU容量和训练强度为代价。因为没有企业或者机构愿意以一种不计成本的方式上马AI,即便这个AI能够处理多线程任务,那还不如“单任务AI+人工”来的更加现实。
目前看来,成本更低的PopArt大有可为。
说了这么多,回到最开始的问题,AI的多任务处理能力真的超越人类了吗?
从苛刻的实验室数字角度讲,是的。但从广泛定义的智慧角度看,机器的每一点进步都还依赖于不断模拟和接近人脑的水平,距离否定人类本身的价值,还早着呢。
目前看来,处理多任务的学习能力更大的作用,还是提升AI在产业应用上的工程能力,用更高的智能为生活带来便利。

时间:2018-10-29 23:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















