一文读懂机器学习中的模型偏差
什么是ML模型的公平和偏差
机器学习模型中的偏差是由缺乏足够的特征和用于训练模型的相关数据集不全面引起的。鉴于用于训练模型的特征和相关数据是由人类设计和收集的,数据科学家和产品经理的偏见可能会影响训练模型的数据准备。例如:在收集数据特征的过程中,遗漏掉一个或多个特征 ,或者用于训练的数据集的覆盖范围不够。换句话说,模型可能无法正确捕获数据集中存在的基本规则,由此产生的机器学习模型最终将出现偏差(高偏差)。
可以通过以下几个方面进一步理解机器学习模型偏差:
缺乏适当的功能可能会产生偏差。这样的模型是欠拟合的,即模型表现出高偏差和底方差。 缺乏适当的数据集:尽管功能是适当的,但缺乏适当的数据也会导致偏见。大量不同性质的(覆盖不同场景的)数据可以解决偏差问题。然而,必须注意避免过度高方差,这可能会影响模型性能,因为模型无法推广所有类型的数据集。
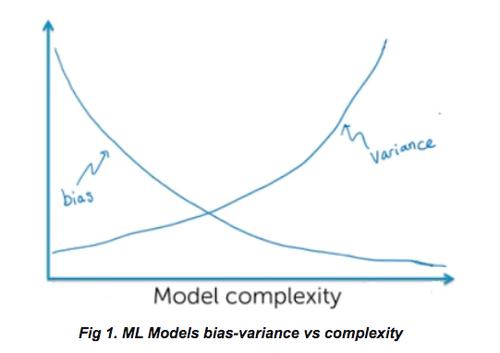
如果发现模型具有高偏差,则该模型将被称为不公平,反之亦然。需注意的是,减少偏差的尝试可能会导致具有高方差的高复杂度模型。下图代表了模型在偏差和方差方面的复杂性。
注意:随着偏差的减小,模型越来越复杂,可能会出现高方差。
如何测试ML模型的公平/偏差
想要测试ML模型是公平的还是存在偏见的,首先要了解模型的偏见程度。常见的方法是确定输入值(与特征相关)在模型预测/输出上的相对重要性。确定输入值的相对重要性将有助于使模型不过度依赖于讨论部分的受保护属性(年龄、性别、颜色、教育等)。其他技术包括审计数据分析、ML建模流水线等。
为了确定模型偏差和相关的公平性,可以使用以下框架:
Lime FairML SHAP Google What-If IBM Bias Assessment Toolkit
偏差的特征和属性
以下是导致偏差的常见属性和特征
种族 性别 颜色 宗教 国籍 婚姻状况 性取向 教育背景 收入来源 年龄
考虑到上述特性相关的数据可能导致的偏差,我们希望采用适当的策略来训练和测试模型和相关性能。
AI偏见在行业中的示例
银行业务:由于系统中引入的模型,其训练数据(如性别、教育、种族、地点等)存在偏见,导致一个有效的贷款申请人贷款请求被拒。或者一个申请人的贷款请求被批准,但其实他并不符合批准标准。
保险:因为预测模型数据集涵盖的特征不齐全,导致一个人被要求支付高额的保险费。
就业:一个存在偏见的机器学习模型,根据候选人的种族、肤色等属性错误的筛选候选人的简历,导致有资质的候选人被筛选掉,致使公司错失聘用优秀候选人的机会。
住房:在住房领域,可能会因为位置、社区、地理等相关数据,在引入过程中出现偏差,导致模型具有高偏见,对房价做出了错误的预测,最后致使业主和客户(买方)失去交易机会。
欺诈(刑事/恐怖分子):由于训练模型对种族、宗教、国籍等特征存在偏见,将一个没有犯过罪行的人归类为潜在罪犯且进行审问。例如,在某些国家或地区,某一宗教人士被怀疑成恐怖组织。目前,这变成了个人偏见的一部分,而这种偏见在模型中反应了出来。
政府:假设政府给某一特定人群设定政策,机器学习负责对这些计划中的收益人群进行分类。模型偏见可能会导致本应该享受相关政策的人群没有享受到政策,而没有资格享受相关政策的人却成为政策受益人。
教育:假设一位学生的入学申请因为基础的机器学习模型偏见被拒绝,而原因是因为使用模型训练的数据集不全。
金融:在金融行业中,使用有偏差的数据建立的模型会导致误批申请者的贷款请求,而违反《平等信贷机会法》。而且,误批之后,用户会对最终结果提出质疑,要求公司对未批准原因进行解释。
1974年,法律规定,禁止金融信用因为种族、肤色、宗教、性别等属性歧视任何人和组织。在模型构建的过程中,产品经理(业务分析师)和数据科学家需要尽可能考虑所有可能情况,确保构建模型(训练或测试)的数据的通用和准确,无意中的一丝细节就可能导致偏见。
总结
通过阅读本文,您了解了机器学习模型偏差、偏差相关的属性和特征以及模型偏差在不同行业中的示例。导致偏差的原因可能是因为产品经理或数据科学家在研究机器学习问题时,对数据特征、属性以及用于模型训练的数据集概括不全面,导致机器学习模型无法捕获重要特征并覆盖所有类型的数据来训练模型。具有高偏见的机器学习模型可能导致利益相关者采取不公平/有偏见的决策,会严重影响整个交易过程甚至是最终客户的利益。

时间:2018-10-17 14:25 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














