Kaggle CTO 力荐:从 Kaggle 历史数据看机器学习
多年来,数据科学领域的许多趋势已经发生了改变。Kaggle,作为全球最大、最受欢迎的数据科学社区,记录着这些变化的演进状态。本文将使用 Kaggle Meta Data 逐一分析,看看这些年来,我们的数据科学究竟发生了什么变化?
线性回归与逻辑回归
线性回归与逻辑回归是机器学习中比较基础又很常用的内容,其中前者可以进行连续值预测,后者能被用于解决分类问题。所以我们先从它们开始,根据 Kaggle 论坛的帖子数对比这两种算法的热度趋势。

蓝:线性回归;橙:逻辑回归
如上图所示,橙线大多数时间都在蓝线之上,用户这些年来似乎一直都更喜欢聊 logistic 回归。而宏观来看,两种算法的变化趋势几乎吻合,峰值重合度较高,虽然起伏明显,但这 8 年来,它们总体是呈上升趋势的。
那么 logistic 回归受欢迎的原因是什么?一个迹象表明,Kaggle 上的分类问题远多于回归问题,其中一个代表是这些年来最受欢迎的泰坦尼克号生存预测竞赛。这是 Kaggle 上历史最 “悠久” 的竞赛之一,用户的讨论自然也很激烈。而最受欢迎的回归问题则是房价预测,但人们通常会在完成泰坦尼克号之后再考虑这个问题。
在 2017 年 10 月和 2018 年 3 月,Kaggle 论坛上关于 logistic 回归的讨论量大幅增加。对此,一个可能的解释是平台上出现的新竞赛——恶意评论分类。当时一些团队分享了不少和分类模型相关的高质量经验,其中就包括 logistic 回归。
XgBoost的霸主地位
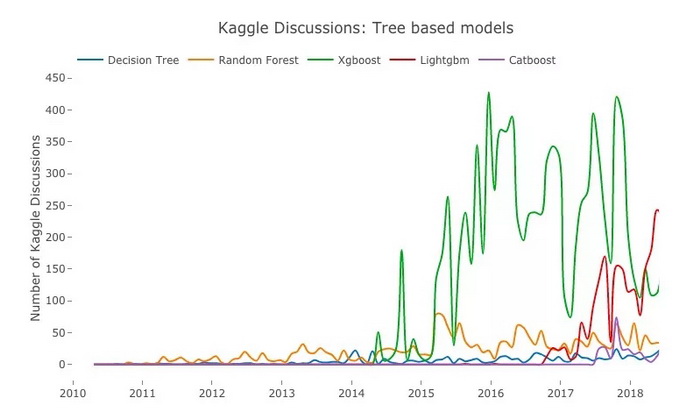
蓝:决策树;橙:随机森林;绿:XgBoost;红:LightGBM;紫:CatBoost
在 2014 年以前,线性模型、决策树和随机森林的讨论量虽然不多,但它们占据绝对话语权。2014 年,时为华盛顿大学博士的陈天奇开源 XgBoost 算法,受到大众追捧,之后它也迅速成了 Kaggle 竞赛中的常客。时至今日,XgBoost 在竞赛中的使用率还是很高,性能也很好,不少夺冠方案中都有它的身影。
但是,根据曲线我们可以注意到,自从 2016 年 LightGBM 被提出后,XgBoost 的讨论量出现了一定程度的下降,而 LightGBM 却一路水涨船高。可以预见,在学界开源更好的模型前,这个算法将在未来几年占据主导地位。现在 LightGBM 也已经出现在不少竞赛中,比如 Porto Seguro 的安全驾驶预测,它的优点是比 XgBoost 实现速度更快、更简单。
除了这些算法,图中 “最年轻” 的 CatBoost 也有走红的趋势。
神经网络与深度学习趋势
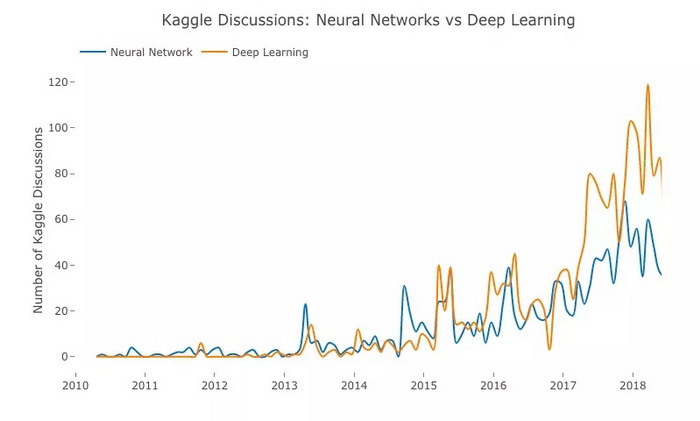
蓝:神经网络;橙:深度学习
几十年来,神经网络在学界和工业界一直不温不火,但如上图所示,随着大型数据集的出现和计算机算力的大幅提升,近几年这种趋势已经发生了变化。
从 2014 年起,我们相继迎来了 theano、tensorflow、keras,与此同时,一个名为深度学习的时代也渐渐出现在世人视野里。在 Kaggle 上,用户发表的有关深度学习的帖子数不断上升,并最终超过神经网络。此外,诸如亚马逊、谷歌等的云服务提供商也正拥抱新技术,以更加积极的姿态展示在云上训练深层神经网络的能力。
深度学习模型是 Kaggle 竞赛中的新星,目前它已经在图像分类、文本分类竞赛中崭露头角,比如 Data Science Bowl、Quora 重复问题分类等。而伴随 RNN、CNN 的不断改进,深度学习的流行趋势似乎已经势不可挡。此外,一些尝试已经证实,迁移学习和预训练模型在竞赛中能够表现出色。
这种技术让人们看到了可能性。为了让用户从实践中学到更多知识,Kaggle 可以推出更多和图像分类建模相关的比赛,但以当前的情况看,现在限制用户大规模使用深度学习的是它的算力要求。但这种问题是可以被解决的。Kaggle 已经添加 GPU 支持,未来,相信尝试深度学习的用户会越来越多。
Kaggle上流行的机器学习工具
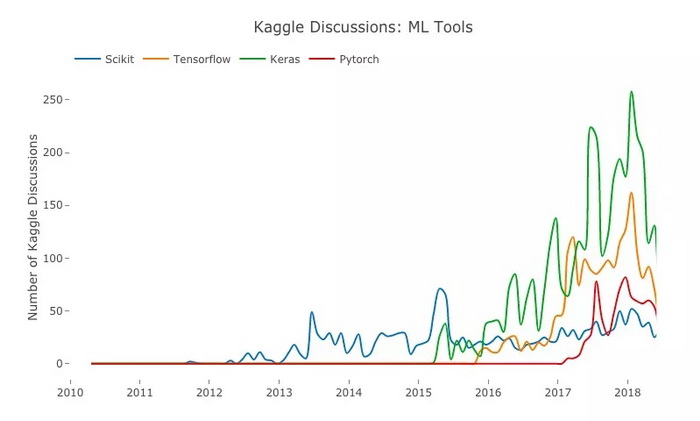
蓝:Scikit;橙:Tensorflow;绿:Keras;红:Pytorch
在 2015 年以前,如果一个数据科学家想构建机器学习模型,Scikit Learn 是他唯一可以选择的库;2015 年后,这种局面发生了改变,作为 ML 生态的一部分,谷歌开源软件库 Tensorflow,并让它迅速在全球范围内普及。
但Tensorflow 也存在缺点,就是它比较难学,因此虽然用户非常多,但在 Kaggle 这个竞赛平台上,大多数用户还是倾向于选择更灵活、更简单的 Keras。毕竟究其本质,Keras 可以被看作是 Tensorflow 封装后的一个 API。
XgBoost vs Keras
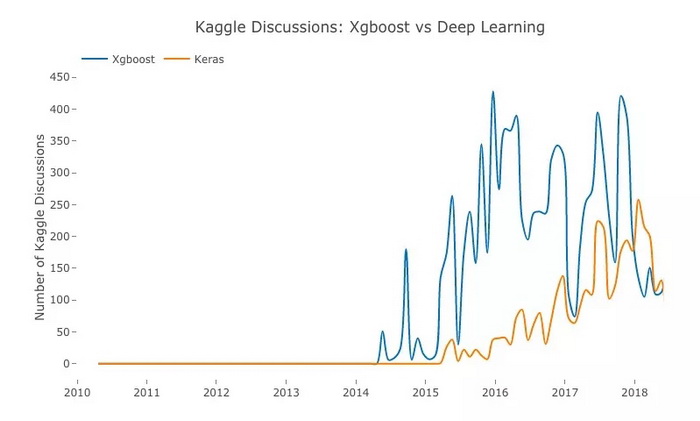
蓝:XgBoost;橙:Keras
既然 Keras 是深度学习框架,我们可以把它看做深层神经网络的间接代表。
XgBoost 与深度学习孰优孰劣?这是去年 Quora 上吵翻天的一个问题。而从 Kaggle 的数据看,前者一直处于领先地位,而后者也在奋力追赶。相比复杂、层多的神经网络,XgBoost 的优点是更快,对硬件要求更低,因此也更受普通用户欢迎。
但这个结果并不代表优劣,拿陈天奇博士自己的话说,就是:
不同的机器学习模型适用于不同类型的任务。深层神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而基于树模型的 XGBoost 则能很好地处理表格数据,同时还拥有一些深层神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。
可视化工具大比拼
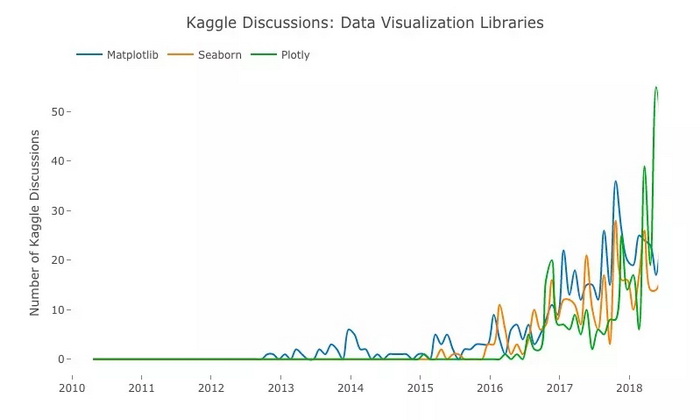
蓝:Matplotlib;橙:Seaborn;绿:Plotly
从 2017 年起,Plotly 就像开了挂一样一路走红,现在已经成为 Kaggle 用户最常用的可视化工具。排名第二的是 Seaborn,它实际上是在 Matplotlib 的基础上进行了更高级的 API 封装,生成的图更好看,而作为补充,Matplotlib 的图更有特色。
数据科学过程步骤大比拼
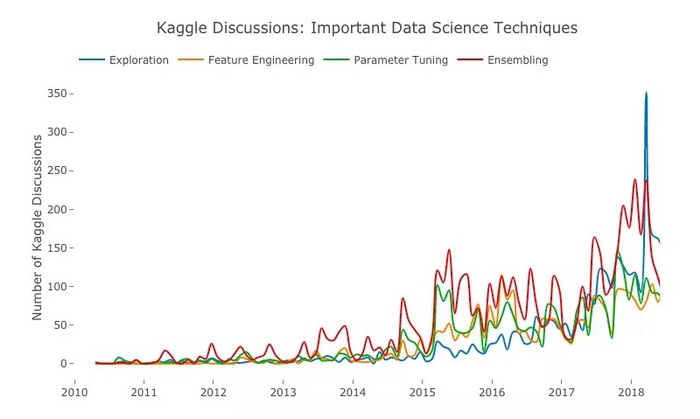
蓝:Exploration;橙:特征工程;绿:调参;红:集成
在上图中,最受 Kaggle 用户关注的是模型的集成。参加竞赛时,虽然最后提交的是一个模型,但参赛者会先训练若干个弱模型,最后再用集成方法进行整合堆叠。这种做法在回归和分类任务中非常常见。
至于同样倍受瞩目 Exploration,近期,无数数据科学家已经一遍遍强调了探索性数据分析(EDA)的重要性,而他们的呼吁起到了效果。如果我们没法确保数据的可靠性,最后的模型很可能会出问题。
但对于这个结果,有些人可能会感到意外。因为如果想在竞赛中取得好名次,调参和模型微调肯定必不可少,但这两个时间、精力消耗的 “大户” 的排名却不高。所以我们应该牢记,虽然集成是建模过程的最后一步,但我们应该在特征工程和模型调整上投入相当长的时间。
最为人津津乐道的子平台
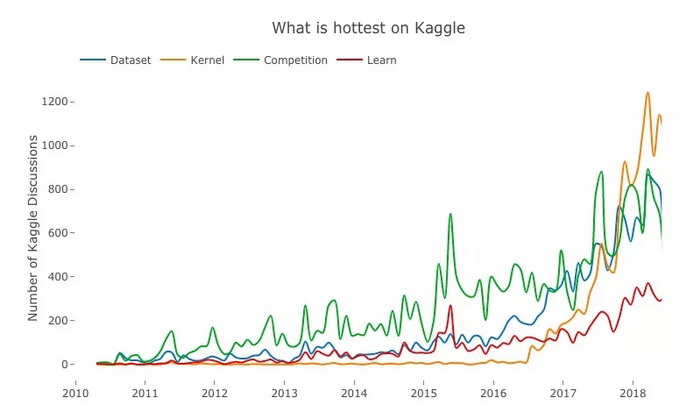
蓝:数据集;橙:Kernel;绿:竞赛;红:Learn
既然 Kaggle 是个数据科学竞赛平台,用户们讨论的内容自然是参加什么竞赛,用了什么数据集,并分享看到的实用代码。而根据上图的曲线,自从 2016 年推出后,代码 Kernel 的受欢迎度一路飙升,毕竟用户们可以在上面看到其他参赛者自愿公开的模型代码,这对于学习和交流来说是不可多得的优质资源。
此外,Kaggle 还推出了课程子平台 Kaggle Learn,虽然目前在讨论度上不及数据集、Kernel 和竞赛,但这些课程主要面向初学者。未来,随着课程内容的丰富和新手人数的增加,这个板块的流行指日可待。
原文地址:www.kaggle.com/shivamb/data-science-trends-on-kaggle

时间:2018-08-14 18:29 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关推荐:
网友评论:















