从“深度伪造”到“深度合成”:AI为啥需要一次
自从2017年Deepfake(深度伪造)横空出世以后,人们惊呼原来AI在造假方面简直天赋异禀。此后“AI生成内容”技术,特别是GAN算法的突飞猛进更加印证了这一事实。不仅仅是AI换脸,还有AI自动生成文本、语音、图像、视频等等一切数字内容。
除了AI换脸带来的色情视频泛滥之外,人们更进一步担心AI生成内容技术在隐私侵犯、威胁信息安全、操纵政治选举等方面带来全新挑战。
人们往往会假设,如果任由AI生成的内容在互联网中蔓延,将会更进一步冲毁互联网世界的真实性边界。

(被AI造假的扎克伯格“讽刺”自己的Facebook平台)
Deepfake之后,真相何在?
如果哪些是真,哪些是假,普通人都难以分辨的时候,那么组成社会基石的真相和信任将就此坍塌,但我们似乎还没有做好活在“无信任社会”的准备吧。
德国哲学家康德在《实践理性批判》中论证“人为什么不能说谎”的法则,揭示了“无信任社会”的悖论和荒谬。
假如“人人可以说谎”是一条社会的通行法则,那么,每个人都不会再信任另一个人说的话,这样说话人的谎言也就不会得逞。说谎而无人相信,就陷入了自相矛盾的境地,反之“人人不能说谎”,才应该是正常社会的通行法则。
这就是说,只有在默认“人人应该诚实”的信任社会里,说谎者才可以通过成功骗到他人获利,也会因为谎言被戳穿而信誉破产。而在“无信任社会”中,信息的真假判断都难以进行,那只能默认一切都为“假”,才会不至于上当受骗。但是相应的代价是信任全无,合作难以达成,交流也不再可能,最终将会是社会的分崩离析。
当然这只是理论上面最极端的演绎。现实世界永远会在理论世界之下形成巨大的灰色空间,人性的基石仍将亘古不变,技术的演进也会一往无前,而人性的弱点就会在这两者的撕扯的张力中一直暴露无遗。每一代的新人类除了持续的学习、进化,以适应技术加速带来的全新挑战,似乎也没有什么更好的办法。
回到“Deepfake”为代表的“AI生成内容”技术来说,它既不会成为将我们的社会拖向“无信任”的深渊,也不会让我们的人性变得更好或更坏一点。在一个即将到来的“虚实相容、真假不分”的后真相世界当中,只会让适应这一变化的我们变得更加复杂和反脆弱。
所以。这一略带“贬义”的Deepfake(深度伪造)的技术名词,需要被我们重新塑造为一个技术中性词汇——Deep Synthesis(深度合成)。
为“深度合成”正名:AI的技术中性
科技的每一次突破,都可能带来意想不到的“副产品”。就如同爱因斯坦发现了质能方程式之后,即使再不情愿,他也无法阻止原子弹的出现和使用。就在Deepfake这个“妖孽”在美国新闻网站Reddit被放出来之后,AI的领军人物Yann LeCun也在Twitter上深深反省:
“说真的,要是当初知道卷积神经网络(CNN)会催生Deepfake,我们还要不要发表它?”
随即LeCun自己就回答了这个问题。LeCun表示,即使不是我们首先公开发表,CNN也会由其他人或机构发明出来。而在2002年当时被公布出来以后,人们也不知道如何来利用它。
换句话说,CNN的价值要在技术人员的不断探索下才能挖掘出来。现在CNN正在被开发出各种各样的应用,既对世界有很多正向的积极影响,比如医疗诊断、自动驾驶、内容过滤以及安全监控等等,也可能引起一些负面的效果,比如侵犯隐私、造假诈骗、偏见歧视等等,好坏参半,可以各打五十大板。
简单来说,就是AI无罪,问题还是出在使用AI技术的人类身上。
以Deepfake技术所引发的AI换脸的色情视频泛滥来说,AI技术被应用于色情产业几乎是一件“必然如此”的过程。一方面,现代色情产业一直都是最新科学技术应用的急先锋,另一方面,AI在图像内容生成技术的发展正好迎来了突破临界点。最后一步就只剩下这个叫“Deepfakes”的用户最后的“灵机一动”了。
实际上,Deepfake为“AI内容生成”技术的普及起到了推波助澜的作用,但同时也带来难以抹去的污名化影响。而鉴于“AI内容生成”技术的发展早已超出AI换脸的范畴,技术商业领域正在试图用“深度合成”来为这一技术正名。
首先,Deepfake(深度伪造)一词明显以偏概全,其仅仅是“AI换脸”技术的早期代表,不足以包含所有的“AI生成内容”的技术。用Deep Synthesis(深度合成)可以更好地泛指所有AI生成算法和涵盖自动生成图像、视频、语音、文本、音乐等内容的合成技术。
其次,Deepfake尚未得到技术社区的广泛认可,只是被媒体大众叫顺嘴了而已。况且Deepfake自带的“腹黑”体质,对于AI技术的应用推广会带来直接的负面影响。
“深度合成”这个更为中性的技术名称,将会代替Deepfake来行使AI内容发展的应尽之责。那么,“深度合成”该如何撑起这重任呢?
“深度合成”的底气:技术加速和商业落地
“深度合成”技术,其实就是借助可以自主学习的深度学习算法模型来实现的,其主要使用的的两个技术就是“自动编码器”人工神经网络和 “生成对抗网络”(GAN)的人工神经网络组成。
前者用于训练数据的合成,后者由生成器和鉴别器组成,一个用来进行新数据的生成和一个用来对其进行鉴别,经过二者无数次的对抗,最终生成出“以假乱真”的合成数据,其中就包括Deepfake所创造出来的换脸视频。
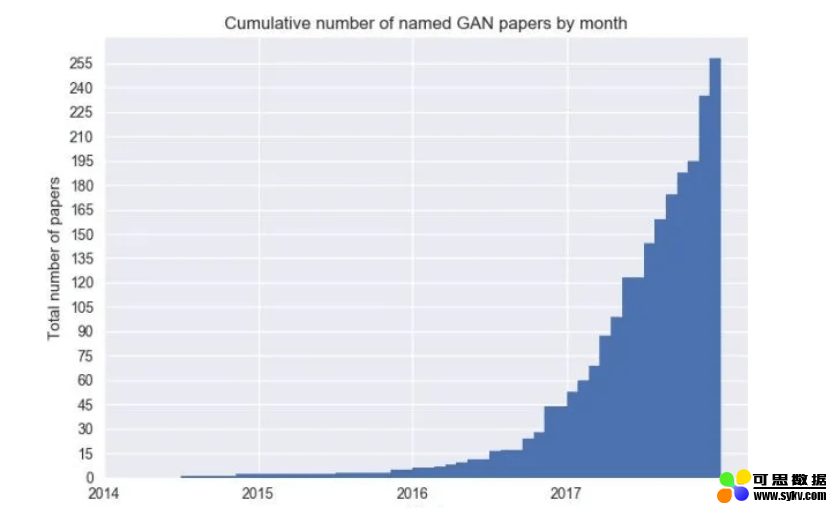
(GAN相关论文的发表情况)
从2014年,GAN提出一直到今天,已经经历了从CGAN、BigGAN 、StyleGAN等多个版本更新,其中每年的相关研究论文也在加速增长,可见学界对于GAN算法的重视和发展前景的看好。

(BigGAN 生成的包含各种类别的高清晰图片)
与此相应的,就是图像生成质量的突飞猛进,其中不仅可以实现人脸的合成,也能更一步实现图像叠加融合,或者直接生成全新的高清图片,以致于人眼根本难以分辨真假。
比如,去年MIT和IBM沃森联合实验室发布的一个基于GAN的AI艺术画师,就可以学习文艺复兴时期的画家的绘画风格,直接将现代人类的照片变成文艺复兴时期的画作。

其中的技术优势在于,GAN神经网络会根据自己学到的技巧为画面重新构图,也就是它是画出新的图片,而不是利用风格迁移的方式,改变原图的色彩。
其实,深度合成技术已经可以走得更远。除了单一的图像、音频合成之外,多维度的内容合成已经是一个趋势,这样可以将语音识别、人脸识别、唇形搜索等结合起来,进行人脸语音的合成,从而可以让一个人自然流利地说出自己从未说过的话。

此外,人脸合成之外,全身合成、3D合成虚拟人技术也成为当前的应用热点。刚刚过去的两会期间,搜狗联合新华社推出上岗的全球首个3D版AI合成主播,就已经可以在文本实时驱动面部表情和唇形,肢体动作、超写实细节呈现上面做到比拟真人的动态效果。
在“深度合成”技术的商业化方面,已经有众多行业和企业看到其应用场景和广阔市场。目前,“深度合成”已经在影视娱乐、社交通讯等多个行业的场景中开始发挥作用。
比如,在影视剧制作中,最直接的帮助就是提升音视频制作的效率,拓展创作想象空间。一些特殊情况下,还可以通过合成技术为影视剧的失声的演员进行声音合成,为已过世的演员进行“数字复活”,甚至直接创造虚拟数字人来进行影视剧集的制作。
在娱乐应用体验上面,最基本的脸部特效应用、换脸视频、动图,都已经多次在我们的生活中出现;虚拟偶像、虚拟主播、虚拟客服也随着深度合成技术的成熟而变得越逼真和可信。
在社交通讯上面,与其担心深度合成技术会暴露个人隐私,不如可以让深度合成技术帮我们在社交网络中建立自己的“数字分身”,就如同《头号玩家》里面每个人创建的虚拟形象一样,成为自己在网络世界的通行证。
此外,像电商营销、教育艺术、医疗科研等领域,深度合成技术带来的仿真数据和虚拟化内容都可以为这些产业带来新的应用场景或者直接推动该领域的技术进步。
显然,深度合成技术的这些正向价值正在为其换来更有底气的话语权和发展前景。但是这个一出现就饱受人类质疑和恐惧的AI技术,仍然值得我们认真对待其应用边界和规则。
“深度合成”的治理:如何锁住“虚假内容”的恶龙
正如一切获得都必须付出代价一般,我们如果想要享受深度合成技术带来我们的一切生活便利和精神享受,同时就必须承受其带来的将数字世界全面虚拟化的代价。深度合成技术所带来的“虚假内容”的社会风险将长期存在。
- 首先,深度合成的开源技术和软件,让普通人们伪造、操纵音视频的门槛大幅降低;
- 其次,这些虚假音视频内容足以以假乱真地骗过大多数“不明真相”的群众;
- 最后,这些带有明显色情、危言耸听或侵犯隐私的信息又足以吸引人,只要从源头传出,就会进行源源不断的扩散。
除了少数能够辨别真伪的专业人士,大多数人都难以分辨和抵制这些假信息的诱惑。深度合成的技术滥用风险,需要得到来自法律、技术、行业、民众等多方面的制约。
- 第一,法律层面。对AI深度合成内容的用途、标记、使用范围以及滥用技术的处罚,都应该进行深入研究,并出台相应的规定,为深度合成的合法使用提供依据。
- 第二,技术层面。与深度合成技术同步进化的内容鉴别技术和溯源追踪技术也应该得到重视。针对合成内容的有效鉴别与标记,才能从源头来识别合成内容,以防止负面的虚假内容的扩散。
- 第三,行业层面。深度合成技术离不开行业自律,合成内容技术提供者和平台要承诺在合成内容之上必须做出标记,或者提供有效的检测和标注工具,来保证合成内容被清晰识别出来。
- 最后,民众层面。相比较于权威机构或者主流精英人群对合成内容泛滥的担忧,广大民众反而可能是这波“虚拟化”浪潮最主要的支持者,甚至是虚假信息的推波助澜者。
在我们即将全面迎来数字化世界的今天,培养合格“数字素养”应该要成为一件从小就抓起的公民必修课。但这门课教什么、怎么上,仍然需要在深度合成技术发展的路上慢慢探索。
正如没有任何一个技术是我们在做好准备之后才出现,AI技术也是如此。从一开始,我们就把AI技术出发点定义为,尽可能地学习和模仿人类的能力,以致于最终能够代替人类行驶那些繁重、重复甚至极高难度的任务。
而深度合成技术不正是这一目标的实现过程。我们既然选择唤醒AI这条巨龙,就不能再“叶公好龙”地担心AI越来越像人类这件事情。
最后,反过来看我们人类这个物种,一方面我们有极致的智慧去探索世界的因果规律,始终去探索那个“真相”;一方面我们又抱着极大热情来发明各种工具,来承担人类的各种工作。
这两种能力也直接促成了我们今天的工业世界,以及未来要进入的数字虚拟世界。
乐观来说,我们不仅不用太过担心“后真相时代”的来临,甚至于,我们还会很快适应这个彻底“虚拟化”的美丽新世界。
对于绝大多数人来说,追求真相,远远没有追求舒适更具吸引力。

时间:2020-06-21 18:41 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















