12个场景应用,百余种算法,AI是如何攻占经济学的?
2020年2月7日,在第34届美国人工智能协会年会AAAI 2020现场,深度学习三巨头齐聚,“计算机视觉”与“机器学习”分座两旁,对最佳论文虎视眈眈。最终清华大学与南洋理工大学的一篇“混合可分割和不可分割商品的公平划分”文章获得最佳学生论文奖。

论文地址:https://arxiv.org/pdf/1911.07048.pdf
这时候人们猛然惊醒,原来,深度学习已经在博弈论和经济学领域布局已久,从论文录取率来看,每三篇录取一篇的录取率已经占据了榜首。这在老牌经济学家眼里似乎不可思议,毕竟经济学研究的重心不在预测方面,而是对于经济现象的解释,经济运作规律的揭示。具象一些,深度学习的黑盒性质无法有效地解释优化好的参数,无法说明参数对经济规律具体作用机制。
但是,AI经济学家运用深度学习也有别样的魅力。
强化学习之于税收设计
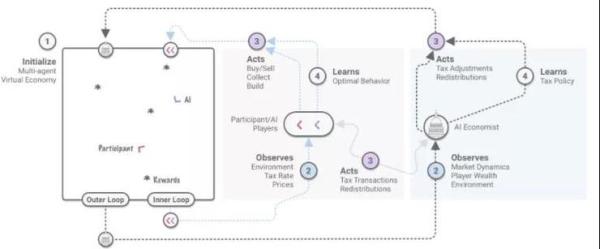
两级学习框架斯坦福大学副教授 Richard Socher 开发了一个包含智能体(工人)和税收政策(政府)的两级强化学习框架,用原生态的经济环境来设计税收政策。
在动态模拟的世界中只设置了两种资源:木材和石材,并假设资源再生的速度有限。工人通过在世界里随机游走收集资源并通过买卖或者盖房子赚钱。钱可以带来效用(满足程度),盖房子付出劳动会降低效用。
另外,给予工人技能不同劳动效率不同的假设,工人赚的钱需要缴税,系统所得税收在所有工人之间平均分配。
平均分配的机制对工人战略眼光进行了要求。当模拟世界中的工人以效用最大化为目标时,整个系统出现了这种状况:低技能的工人自收集和销售,高技能的工人买材料和建筑。
这种状况在经济学中的术语是“分工专业化”,此举能够最大化系统的效用。
在整个模型运行的过程中,用强化学习的最佳税收设计作为奖励模式。政策制定者可以设置税率影响工人税后收入水平,工人通过买卖资源和盖房子获得金钱(效用),强化学习奖励目标是:整体系统效用最大化。
有了这个奖励目标,工人和政策制定者的行动对整个系统带来了内部循环和外部循环两个挑战。
在内部循环中,工人在劳动、挣钱、纳税之中不断调整自己的行为,如果这时候给定其一个固定的税率,那么问题就变成具有固定奖励函数的标准多智能体强化学习问题。
在外部循环中,税收政策的调整是为了优化社会目标。这就形成了一个非静态的学习环境,在这个环境中,强化学习中的智能体需要不断地适应不断变化的效用环境。
最后,作者发现通过使用学习税率表(类似美国所得税的征税方式)和熵正则化等技术,可以找到稳定的收敛点。实验结果表明,通过强化学习的AI经济学家能在提高47%的平等性的同时,只降低11%的生产率。
在虚拟世界中模拟现实经济状况,想法设计更好的制度只是AI和经济学结合方式之一。其实深度强化学习在面临风险参数和不确定性不断增加的现实经济问题时,也可以提供更好的性能和更高的精度。
深度学习在经济学中的应用

论文下载:https://arxiv.org/ftp/arxiv/papers/2004/2004.01509.pdf
在论文《经济学中的强化学习》(Comprehensive Review of Deep Reinforcement Learning Methods and Applications in Economics)中,德累斯顿理工大学和牛津布鲁克斯大学的研究员们细数了强化学习在经济学中的表现。
通过对股票定价、拍卖机制、宏观经济等12个领域的调查,发现深度学习算法比传统的经济、统计学算法在精确度和稳健性发现要更加优秀。
1、深度学习下的股票定价
股票价格有着极强的不确定性和风险性,如果能有模型攻克股价预测,无疑会给模型建造者带来巨额收益。关于用深度学习预测股价的最新进展如下表所示。
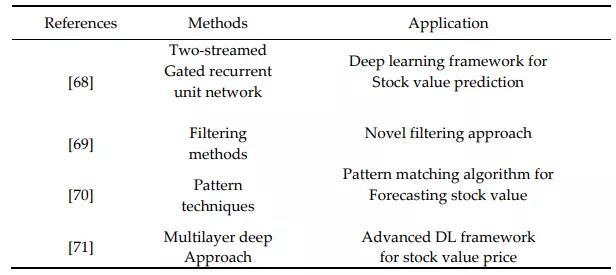
情绪对股价走势无疑非常重要,当前的大多数研究依赖于低效的情绪数据集,这往往会导致模型性能不佳,[68]提出的两流门控循环单元发现比LSTM模型性能更佳。另外他们提出了Stock2Vec嵌入模型,并在使用哈佛IV-4的同时,对模型的稳健性进行了市场风险的证明。
- [69]提出了一项聚光灯下的深度学习技术(spotlighted deep learning )应用于股价预测,主要创新点是滤波技术赋予了深度学习模型新颖的输入特征。
- [70]在分析股票价格模式的同时,利用深度学习技术对股票价值流进行了预测,具体是利用时间序列技术设计了一种DNN深度学习算法来寻找模式,虽然准确度有86%。但是,DNN存在拟合过度、复杂度高等缺点,因此建议使用CNN和RNN。
- [71]的研究中,采用了一种新的多层深度学习方法,利用时间序列的概念来表示数据,从而能够预测当前股票的收盘价。
2、深度学习下的保险业
保险业现在面临的问题是,如何有效地管理欺诈检测。相应的,机器学习技术针对此问题,逐渐开发了测量所有类型风险的算法。

- [75]等人利用社会化网络分析法检测大数据集的汽车保险职业欺诈。他们用循环概念构建了间接碰撞网络( indirect collisions network),在更现实的市场假设下,此网络能够识别可疑的循环,从而获得更多利润。另外,他们还通过实际数据得出的造假概率,对可疑成分的方法进行了评价。
- [76]等人采用LDA和DNNs技术相结合的方式提取事故的文本特征,发现其性能优于传统的方法。另外,为了考虑LDA对预测过程的影响,他们还在“有LDA”和“无LDA”两种情况下,通过准确度和精确度性能因子对结果进行评估。
- [77]等人提出了一种结合自动编码技术和远程信息处理数据值的算法来预测与保险客户相关的风险。
3、深度学习下的拍卖机制
拍卖机制的核心是:投标人需要规划出最大化利润的最优策略。最新的研究成果如下表所示:
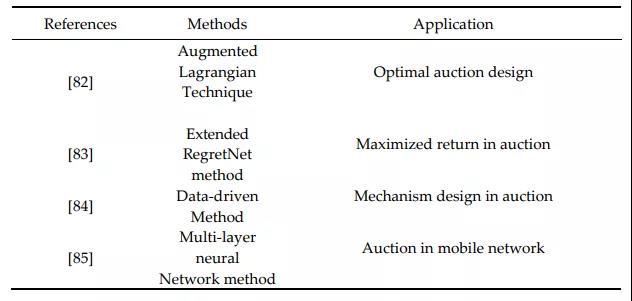
- [83]等人在预算约束和贝叶斯兼容性方面对[82](增广拉格朗日法)中的结果进行了扩展。他们的方法证明了神经网络能够通过关注不同估值分布的多重设置问题,有效地设计出新颖的最优收益拍卖。
- [84]等人采用了数据为导向的方法。具体方法:假定可以对每个投标者应用多个投标的前提下利用策略专业知识。
- [85]等人是使用多层神经网络技术构建了一种有效的拍卖机制,并应用于移动区块链网络。
- [86]设计了一种多投标人的兼容拍卖机制,具体通过应用多层神经网络对其机制进行编码,从而最大化了利润。与基于线性规划的方法相比,采用增广拉格朗日技术的方法能够解决更复杂的任务。
4、深度学习下的银行和在线市场
在网上购物和信用卡场景中对欺诈检测要求非常高,当前强化学习最先进的研究成果如下表所示:
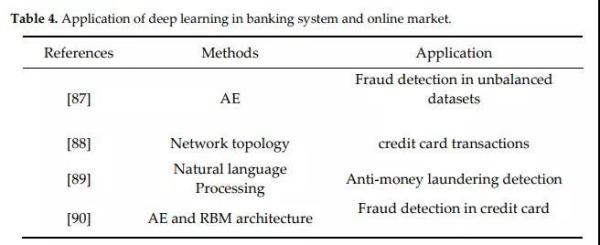
- [90]应用基础实验证实了AE(自动编码)和RBM(玻尔兹曼机)方法能够在海量数据集下准确地检测信用卡的风险。但是深度学习在建立模型时需要利用影响其结果的不同参数。
- [87]提出的研究设计了一种自动编码器算法,建立的高效自动化工具可以处理世界各地日常交易。该模型使研究人员可以在不需要使用欠抽样等数据平衡方法的情况下,给出关于不平衡数据集的报告。
- [89]设计了一个使用自然语言处理(NLP)技术的新框架,能够形成与各种数据源(如新闻和推文)相关联的复杂机制,从而有效检测洗钱活动。
5、深度学习下的宏观经济
宏观经济最重要的问题是指标预测,包括失业率、GDP增长速率等。采用神经网络的方法,最新的研究成果如下图所示:
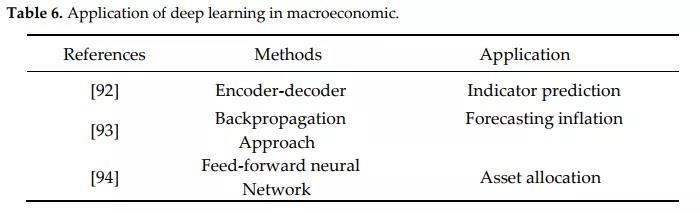
- [92]提出了一种高鲁棒性模型——编码器-解码器模型,利用深度神经架构提高失业问题预测精度,并且精度要求很低。另外,在此基础上,其还采用平均绝对误差(MAE)值来评估结果。
- Haider 和 Hanif [93]构建神经网络预测通货膨胀,其结果由均方根(RMSE)值来评估。
- [94]使用前馈神经网络进行战术性资产配置,同时应用宏观经济指标和价量趋势。他们提出了两种不同的方法来构建投资组合,第一种方法用于估计预期收益和不确定性,第二种方法直接利用神经网络结构获得配置,并对投资组进行优化。
6、金融市场中的深度学习
在金融市场中,有效处理信贷风险至关重要。由于最近大数据技术的进步,深度学习模型可以设计出可靠的金融模型来预测银行系统的信用风险,最新研究如下表:

- [95]使用二进制分类技术给出了选定的机器学习和深度学习模型的基本特征。此外,考虑到贷款定价过程中的关键特征和算法,此研究分别使用这两个模型对贷款违约概率进行了预测。
- [96]研究的方法可以帮助金融机构以较少的工作量进行信用评估,同时能够提高信用评分和客户评级方面的分类准确性。另外,还对线性SVM,CART,k-NN,朴素贝叶斯,MLP和RF技术的精确度进行了比较。
- [97]通过自动编码、校准、验证等过程构建了一个资产组合算法,可以应用于包括看跌期权和看涨期权在内的具有标的股票的投资组合。
- [98]建立了抵押贷款风险的深度学习模型,能够处理庞大的数据集。实验结果发现:受当地经济状况影响的变量与债务人行为之间具有非线性关系。例如,失业变量在抵押贷款风险中占有相当大的比重。
7、深度学习下的投资
财务问题通常需要对多个来源的数据集进行分析。因此,构建一个可靠的模型来处理数据中的异常值和特征非常重要。最新研究成果如下图:
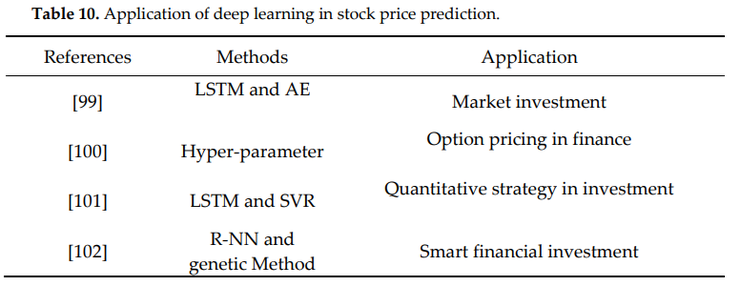
- [99]设计的模型具有提取非线性数据模式的能力。他们使用LSTM、自动编码和智能索引等神经网络体系结构来估计证券投资组合的风险。
- [100]利用DNN结构对期权定价问题进行了研究,以相当高的精度重构了著名的BLACK-SCHOLES期权定价模型计算公式。
- [101]结合交易复杂性研究了期权定价问题,其研究目标是探索高频交易方式下的有效投资策略。其中,LSTM-SVR模型应用于最终交易的预测。
- [102]提出了一种新的学习遗传算法,该算法利用R-NN模型来模拟人类的行为。具体采用了复杂的深度学习结构,包括:强化学习用于快速决策,深度学习用于构建股票身份,聚类用于整体决策目的,遗传用于转移目的。
- [103]通过超参数的多样化选择使模型更加准确。实验结果表明,该模型可以在误差较小的情况下对期权进行定价。
8、深度学习和零售
零售用的最多的是增强现实(AR),此项技术能够改善客户的购买体验。最新研究成果如下所示:
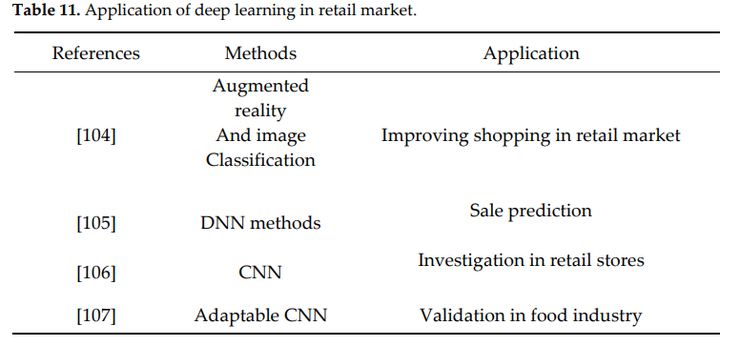
- [104]在一项研究中将深度学习技术和增强现实方法相结合,以便为客户提供丰富的信息。他们还提出了一个移动应用程序,使其能够通过深度学习中的图像分类技术来定位客户。
- [105]设计了一种新的DNN来准确预测未来的销售,该模型使用了一组完全不同的变量,如产品的物理规格和专家的想法。
- [106]等人用CNN回归模型来解决评估商店可用人数和检测关键点的计数这两个问题。
- [107]同时采用k-均值算法和k-近邻算法,将计算出的质心合并到CNN中,以实现有效的分离和自适应。该模型主要用于验证食品生产日期等相关信息。
9、深度学习下的商业智能
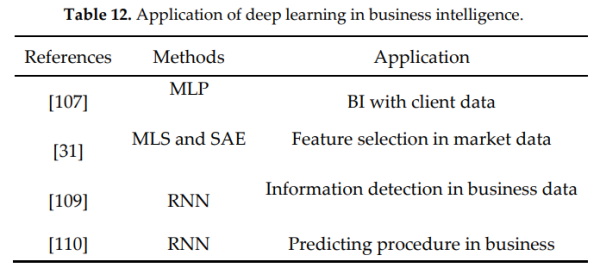
- [108]发展了一项涉及元塑性概念( the concept of meta plasticity)的工作,它具有提高学习机制灵活性的能力,能够从数据中发现更深层次的有用信息并进行学习。研究的重点是MLP,在利用客户数据的同时,输出在BI(商业智能)中的应用。
- [109]提出的MLS和SAE相结合的方法可以用来对序列现象中的时间维进行建模,对于异常情况非常有用,也即业务日志中的异常检测能力较高。
- [31]设计了一种新的多层特征选择,它与堆叠式自动编码器(SAE)交互作用,只检测数据的关键表示。
- [110]使用递归神经网络结构以业务流程的方式进行预测,其中RNN的输入是通过嵌入空间来建立的,在论文中还给出了精度验证结果和该方法的可行性验证结果。
强化学习在高维经济学问题中的应用
前面介绍的是深度学习在经济学领域的应用。对比传统的深度学习,深度强化学习能够有效处理高维问题。所以,在一些包含高维动态数据的经济学问题上,深度强化学习表现更加优秀。
1、深度强化学习下的股票交易
由于缺乏处理高维问题的能力,传统强化学习方法不足以找到最佳策略。下面是深度强化学习的最新研究。
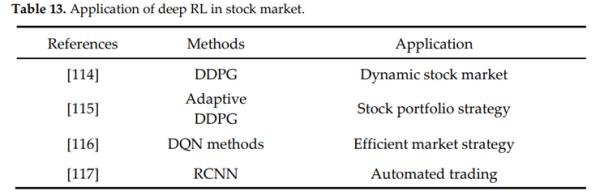
- [114]使用深度确定性政策梯度(DDPG)算法作为一种替代方案来探索动态股票市场中的最优策略。算法处理较大的动作状态空间,兼顾了稳定性,消除了样本相关性,提高了数据利用率。
- [115]等人设计了一种新的自适应深度确定性强化学习框架(Adaptive DDPG),用于在动态复杂的股票市场中发现最优策略。该模型结合了乐观和悲观的Deep RL(optimistic and pessimistic Deep RL),既依赖于负的预测误差,也依赖于正的预测误差。
- [116]为了分析股票决策机制的多种算法,在深度RL中进行了调查研究。他们基于DQN、Double DQN和Dueling DQN三个经典模型的实验结果表明,其中DQN模型可以获得更好的投资策略。另外,这项研究还应用实证数据对模型进行了验证。
- [117]专注于使用深度强化学习实现证券交易中的自动振荡,其中他们使用递归卷积神经网络(RCNN)方法从经济新闻中预测股票价值。
2、深度强化学习下的投资组合管理
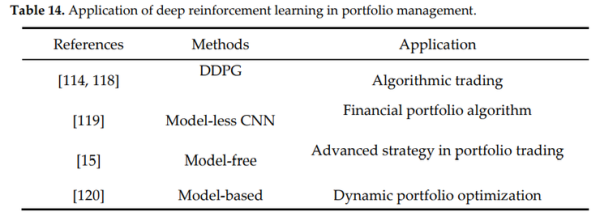
- [118]采用了不同的强化学习方法,例如DDPG方法、最近策略优化(PPO)方法和PG方法。这些方法能够获得与连续行动空间中的金融投资组合相关的策略。他们结合中国资产市场对模型在不同环境下的表现进行了比较,结果表明PG模型在股票交易中比其他两种模型更有利。本研究还提出了一种新颖的对抗性训练方法,能够提高训练效率和平均回报。
- [119]研究设计了无模型卷积神经网络(model-less RNN),其中输入是来自加密货币交易所的历史资产价格,目的是产生一组投资组合权重。
- [15]研究通过充分利用DPG方法来引入奖励函数,以优化累积收益。模型包含了独立评估器集成拓扑结构( Independent Evaluators topology),在权值分担方面结合了大的神经网络集。另外,为防止梯度损坏,还采用了投资组合矢量存储器(Portfolio Vector Memory)。
Yu等人[120]在自动交易的意义上设计了一种新的基于模型的深度强化学习方案,能够采取行动并做出与全局目标相关的顺序决策。该模型体系结构包括注入预测模块(IPM)、生成性对抗性数据增强模块(DAM)和行为克隆模块(BCM),能够用于处理设计的回溯测试。
3、深度强化学习下的在线服务
在线服务主要集中于推荐算法,当前的多种推荐方法,如基于内容的协同过滤(collaborative filtering)、因式分解机器(factorization machines)、多臂老虎机等。但是这些方法大多局限于用户和推荐系统的静态交互,并且关注的是短期奖励。
采用深度强化学习方法目前的进展如下:

- [121]设计的推荐算法使用了行动者-批评者(actor-critic model)模型,可以在连续的决策过程中显式地获取动态交互和长期回报。
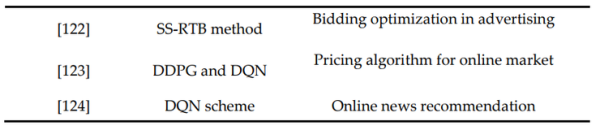
- [122]重点研究了实时竞价(RTB)在与用户行为和竞价策略相关的复杂随机环境下的付费搜索(SS)拍卖。另外,基于阿里巴巴拍卖平台的线上线下评价的实证结果表明了该方法的有效性。
- [123]中提出了一种基于电子商务平台的MDP(马尔科夫链决策过程)框架下的定价算法。由于能够有效地应对动态的市场环境变化,可以设置与复杂环境相关联的有效奖励函数。
- [124]使用DQN( deep Q-network)方案进行在线新闻推荐,能够同时获得当前和未来的奖励。本模型在考虑用户活跃度的同时,还采用Duling Bandit梯度下降法来提高推荐准确率。

时间:2020-05-29 00:03 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















