国内传统企业对Hadoop到底什么态度?

本次调研共耗时两个月(具体话题详见文末链接),共吸引17865人次点击(截至发文时),众多用户围绕Hadoop生存现状主要讨论了以下三大问题:
您对Gartner的报告结论如何看待?就国内现状而言,Hadoop在传统企业的受欢迎程度会和互联网企业相同吗?
您认为Hadoop生态最大的优势和劣势分别是什么?Spark生态也在渐渐完善,其机器学习方面的能力更强,未来与Hadoop生态的关系会是什么样的?
您认为Hadoop生态中表现最好、生命力最旺盛的组件有哪些?为什么?最容易被替换、表现欠佳的组件又有哪些呢?为什么?
(注:为了防止因行业不同而对事情的理解造成偏差,每位答题者被要求给出所属行业,以供用户结合行业属性参考)
一、国内传统行业对Hadoop态度如何?是否与互联网企业一致?
Itpub网友jieforest(制造业): Gartner的调查报告一向有比较高的可信度和权威性,但是Gartner报告未必明确指出Hadoop将在什么时间淘汰。我虽然未读Gartner报告,但我估计其报告应该是讲述当前大数据平台的技术发展趋势。从趋势上看,Hadoop在未来可能会被更好的技术所取代,未来会面临淘汰的风险。
结合今年福布斯大数据市场预测,到2022年,Hadoop市场预计将达到99.31亿美元,复合年增长率为42.1%。从福布斯的数据来看,Hadoop还将兴旺好些年。Hadoop解决方案这些年在国内经过了各公司的检验,大家逐步认识到它是一个成熟靠谱的解决方案,确实能解决企业大数据过程面临的问题,但Hadoop也并非包治百病,有些需求很容易搞定,而有些则很难搞定或者需要另谋别的解决方案。
传统企业往往喜欢采用比较成熟的解决方案,因此Hadoop还将在国内有比较长的生命周期。就像Java语言,现在已经是第10版了,但很多传统企业仍然坚持使用Java SE 6.0。
Itpub网友ceo_lxy(传统制造行业): 在传统制造行业,Hadoop大数据方案感觉实用不强,不是很受欢迎,原因有以下三点:一是传统制造行业没有这么大的数据量,都是内部运营数据及少量供应商和客户数据;二是Hadoop技术更新快且成本较高,制造业利润普遍不高的前提下,Hadoop技术短期带来不了直接回报;三是传统制造行业更青睐成熟的技术方案,而不仅仅是开源。
Itpub网友luckyrandom: 各自面对和专注的领域不同,开发设计也有不同的立场、角度,Hadoop是个更通用的框架和平台。就好像即使MySQL如此流行,但Oracle和SQL Server还是有自己的市场,真正适合用户需求的产品才是好产品,这个产品会包括产品本身质量、发展势头、生态链等。传统企业的量级难以达到“大数据”的级别,除了极少数之外,互联网企业才是Hadoop应用主角。
Itpub网友13572******(金融行业): 大数据杀熟的新闻曝光后,传统企业对大数据的信任度有所下降,大数据的缺点一下子就暴露了出来,只有加强大数据在制造业、农业等领域的应用监管,才可以避免此类投机取巧事件的发生。
Itpub网友aloki(服务业): 我认为Gartner报告有点危言耸听,Hadoop即使在使用过程存在问题,但并不是没办法解决。就国内现状而言,Hadoop在传统企业的受欢迎程度与互联网企业相同,几乎覆盖全行业。
Itpub网友help01(信息服务): Gartner的报告应该还是可信的。在国内,Hadoop应用主要以互联网公司为主,由此可以推断Hadoop在互联网企业比在传统企业更受欢迎。
Itpub网友renxiao2003(传统医疗制造): 上世纪70年代发明的C语言,好多机构和“专家”都曾断言C语言会死,但直到今天C语言依旧是一个流行和不可或缺的开发语言。所以我们不能盲目的去相信报告,要客观的分析和处理。至于Hadoop在传统企业的受欢迎程度和互联网企业肯定是不同的。
二、Hadoop生态目前最大的优势和劣势是什么?未来与Spark的关系更倾向于哪一种方式?
Itpub网友aloki(服务业): Hadoop的优势是可扩展性和容错性,支持从GB到PB级别多种业务需求,支持PB级别海量数据批处理需求;劣势是使用门槛略高,技术迭代快导致学习成本和运维成本升高。Spark大部分情况下与Hadoop配合出现,Spark作为通用计算引擎,而Hadoop提供存储和资源管理框架等服务。
Itpub网友jieforest (制造业) : Hadoop和Apache Spark都是大数据框架,但它们的实现目标有所不同。Hadoop本质上是一个分布式数据基础架构,在大量商品服务器的多个节点上分发海量数据集合,这意味着用户不需要购买和维护昂贵的定制硬件,它还对这些数据进行索引和跟踪,使大数据处理和分析能够比以前更有效。
Spark没有自己的文件管理系统,Spark可以看成是一种数据处理工具,可以对这些分布式数据集进行操作,但其自身不会做分布式存储。Hadoop不仅包含一个称为Hadoop分布式文件系统的存储组件(HDFS),还包含一个名为MapReduce的处理组件,因此不需要Spark即可完成大数据处理。

Itpub网友help01(信息服务): Hadoop的优势有以下几方面,高可靠性:按位存储和处理数据的能力值得信赖;高扩展性:在可用的计算机集簇间分配数据并完成计算任务,这些集簇可以方便地扩展到数以千计的节点;高效性:Hadoop能够在节点之间动态移动数据,并保证各个节点的动态平衡,因此处理速度非常快;高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
劣势:
• 不适合低延迟数据访问;
• 无法高效存储大量小文件;
• 不支持多用户写入及任意修改文件。
Spark目前在国内的大型互联网公司中也得到了积极推广,百度、阿里巴巴、奇虎360、腾讯以及中国移动等都有使用,预计Spark未来会融合到Hadoop生态当中。
Itpub网友renxiao2003 (传统医疗制造) : Hadoop 可以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
不足之处:
• 全量场景,任务内串行
• 重吞吐量,响应时间完全没有保证
• 中间结果不可见,不可分享
• 单输入单输出,链式浪费严重
• 链式MR不能并行
• 粗粒度容错,可能会造成陷阱
• 图计算不友好
• 迭代计算不友好
Hadoop和Spark解决问题的层面不一样:Hadoop和Apache Spark都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多的是一个分布式数据基础设施,它将巨大的数据集分派到由普通计算机组成的集群中的多个节点进行存储,意味着用户不需要购买和维护昂贵的服务器硬件。Spark专门用于对分布式存储数据进行处理,并不会进行分布式数据存储。
Hadoop和Spark可合可分:Hadoop除了提供HDFS之外,还提供了叫做MapReduce的数据处理功能,因此可以完全抛开Spark进行数据处理。相反,Spark也不是非要依附在Hadoop身上才能生存。如上所述,毕竟它没有提供文件管理系统,所以,它必须和其他分布式文件系统集成才能运作。
三、Hadoop生态中哪些组件表现较好?哪些是时候淘汰了?
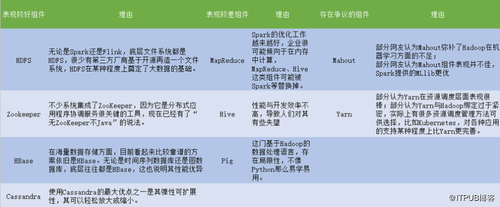
总结
大部分用户认可Hadoop在国内传统企业的应用状况与互联网企业不同,并更倾向于传统企业不如互联网企业应用广泛的观点,主要考虑到传统企业的数据量不如互联网企业多,且传统企业部署Hadoop的成本较高。至于Hadoop与Spark的关系,大多数网友倾向于将Spark与Hadoop集成,以弥补Hadoop的劣势,但是相比较而言,Hadoop略占上风,Spark需要在HDFS之上运行,虽然找到一个替代HDFS的组件并不难,但要想完全还原甚至超越其功能的组件目前还未曾出现在大规模生产验证环境中。

时间:2018-08-10 00:15 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















