从算法到产品:NLP技术的应用演变

第一个与大家分享的Case,基于NLP展开。分为3个部分,分别是NLP的发展、项目叙述、以及Lesson Learned。
讲述NLP的发展,是为了更好地理解这门技术,为项目的展开做铺垫。Lesson Learned是笔者总结整个项目下来自己的收获。
笔者本身并非计算机课班,对理论知识的理解难免不深刻,以及可能会有偏差,请大家不吝指教。
目录:
- NLP的发展
- 项目阐述
- Lesson Learned
一、NLP的发展
1.1 NLP的定义
The field of study that focuses on the interactions between human language and computers is called Natural Language Processing, or NLP for short. It sits at the intersection of computer science, artificial intelligence, and computational linguistics ( Wikipedia)
总结一下维基百科对NLP的定义, NLP关注人类语言与电脑的交互。
使用语言,我们可以精确地描绘出大脑中的想法与事实,我们可以倾诉我们的情绪,与朋友沟通。
电脑底层的状态,只有两个,分别为0和1。
那么,机器能不能懂人类语言呢?
1.2 NLP的发展历史
NLP的发展史,走过两个阶段。第一个阶段,由”鸟飞派“主导,第二个阶段,由”统计派“主导。
我们详细了解一下,这两个阶段区别,
阶段一,学术届对自然语言处理的理解为:要让机器完成翻译或者语音识别等只有人类才能做的事情,就必须先让计算机理解自然语言,而做到这一点就必须让计算机拥有类似我们人类这样的职能。这样的方法论被称为“鸟飞派”,也就是看鸟怎样飞,就能模仿鸟造出飞机。
阶段二,今天,机器翻译已经做得不错,而且有上亿人使用过,NLP领域取得如此成就的背后靠的都是数学,更准确地说,是靠统计。
阶段一到阶段二的转折时间点在1970年,推动技术路线转变的关键人物叫做弗里德里克. 贾里尼克和他领导的IBM华生实验室。(对IBM华生实验室感兴趣的朋友可以阅读吴军老师的《浪潮之巅》,书中有详细讲述。)
我们今天看到的与NLP有关的应用,其背后都是基于统计学。那么,当前NLP都有哪些应用呢?
1.3 目前NLP的主要应用
当前NLP在知识图谱、智能问答、机器翻译等领域,都得到了广泛的使用。
二、项目阐述
2.1 业务背景
说明:在项目阐述中,具体细节已经隐去。
客户是一家提供金融投融资数据库的科技公司。在其的产品线中,有一款产品叫做人物库,其中包括投资人库和创始人库。
- 创始人库供投资人查看,使用场景,当投资人考察是否要投资创业者,因此会关注创业者的学校(是否名校)、工作(大厂)、以及是否是连续创业者、是否获得荣誉,如“30 under 30”。
- 投资人库供创业者查看,使用场景:当创业者需要投资人,会考察投资人的投资情况。因此会关注投资者的学校(是否名校)、工作(大厂)、投资案例、投资风格等
我提供的服务,便是为这两条产品线服务。因为本项目主要关注,相关人物的履历信息,因此该项目代号为「人物履历信息抽取」。
需要抽取的人物履历信息,由5个部分组成:学校、工作、投资(案例)、创业经历、获取荣誉。
2.2 项目指标
项目指标包括算法指标与工程指标。
2.2.1 算法指标
算法层面,指标使用的是Recall和Precision。为了避免大家对这两个指标不太熟悉,我带大家一起回顾一下。
我们先来认识一下混淆矩阵(confusion matrix)。混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。矩阵中的每一行,代表的是预测的类别,每一列,代表的是真实的类别。
通过混淆矩阵,我们可以直观地看到系统是否混淆了两个类别。
我们可以举一个混淆矩阵的例子:
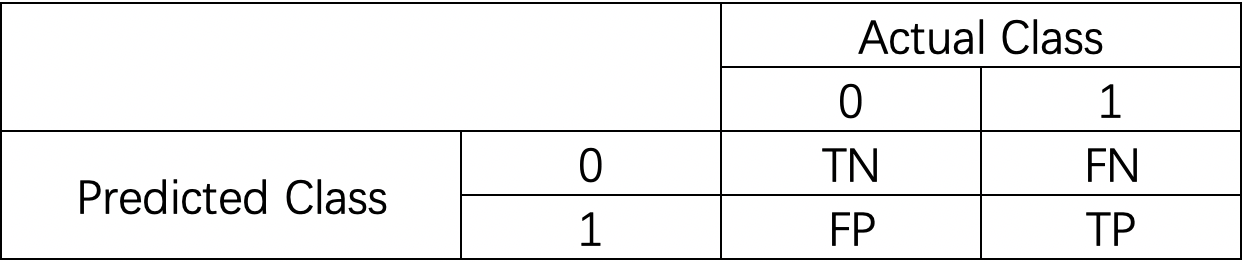
0代表Negative,1代表 Positve。
- TN:当真实值为0,且预测值为0,即为TN(True Negative)
- FN:当真实值为1,而预测值为0,即为FN(False Negative)
- TP: 当真实值为1,且预测值为1,即为TP(True Positive)
- TN:当真实值为0,而预测值为1,即为FP(False Positive)
除了上面,我们还需要了解下面三个指标,分别为Recall、Precision、和F1。
- Recall(召回率)是说我们的Predicted Class中,被预测为1的这个item的数量,占比Actual Class中类别为1的item的数量。如果,我们完全不考虑其他的因素,我们可以将所有的item都预测为1,那么我们的Recall就会很高,为1。但是在实际生产环境中,是不可以这样操作的。
- Precision(精准率)是说,我们预测的Class中,正确预测为1的item的数量,占比我们预测的所有为1item的数量。
- F1是两者的调和平均。
Ok~了解了上面这些衡量算法模型用到的基础概念之后,我们来看看本项目的指标。
模型算法指标为:recall 90;precision 60。
一个思考题?为什么recall 90,precision 60?以及,为什么没有f1,或者说为什么不将f设置为72,因为如果recall 90,precision60,那么这种情况下,f1就是72嘛。
要回答上述问题,我们要从业务出发。需要记住,甚至背诵3遍。
为什么,制定指标的时候,一定要从业务出发呢?
我们来举一个很极端的例子,如果一个模型能做到recall90 precision90,是不是能说这个指标就很好了?
我相信绝大多数场景下,这个模型表现都是十分优秀。请注意,我说的是绝大多数,那么哪些场景下不是呢?
比如说,癌症检测。
假设,你目前在紧密筹备一个“癌症检测”项目。对于每一个被检测的对象,都有如下两个结果中的任意一个结果:
- 1 = 实在抱歉,你不幸患上了癌症。
- 0 = 恭喜你,你并没有换上癌症。
你同事告诉你了一个好消息,你们模型的在测试集上的准确率是99%。听起来很棒,但是你是一个严谨认真的AI PM,所以你决定亲自review一下测试集。
你的测试集都被专业的医学人士打上了标签。下面你测试集的实际情况
- 一共有1,000,000(一百万张医学影像图)
- 999,000医学影像图是良性(Actual Negative)
- 1,000医学影像图是恶性(Actual Positive)
有了上述的数据,即我们模型验证的GroundTruth,接着,我们来看看这个模型的Predicted Result。既然,我们上面学了confusion matrix,那么我们回顾一下Confusion Matrix的两个特征,行代表Predicted class,列代表Actual class。让我们看一下:
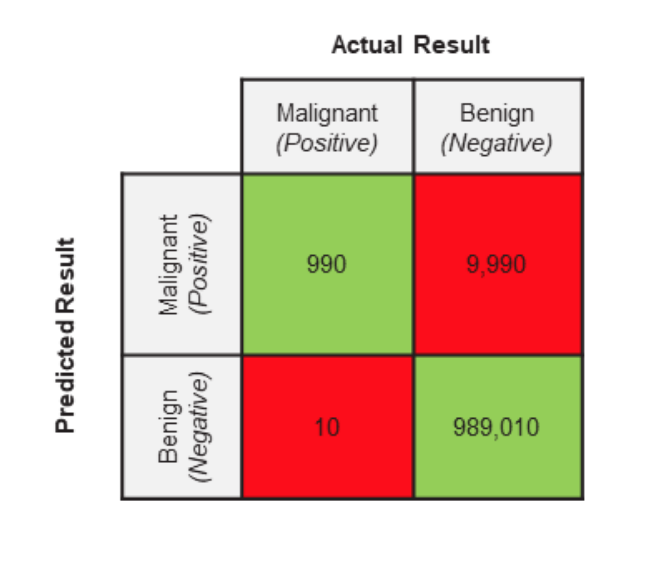
根据所学,实际应用一下:
- TP(实际是Malignant,预测是Malignant)
- FP(实际是Benign,预测是Malignant)
- TN(实际是Benign,预测是Benign)
- FN(实际是Malignant,预测是Benign)
看到这里可能有点头晕,没关系,我马上为大家总结一下:模型正确的判断是1和3,不正确的判断是2和4.
我们希望这个模型将医学影像图片是否为恶性肿瘤做好的区分,好的区分就是指的1和3。除此之外,其余的都是错误的区分。
到这里,我们再看看看模型的表现。
当同事告诉我们模型的正确率是99%的时候,她到底说的是什么呢?我们来仔细分析一下哦~

时间:2020-03-31 23:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















