从开放域机器人构建出发,聊聊如何与机器人吹
作者从自己的实际工作出发,以儿童机器人场景为例,从多个角度对如何构建闲聊机器人进行了阐述,并分享了与机器人“吹水的”价值、方式方法以及背后原理。

一、机器人概述
机器人按照对话方式,可以分为“问答机器人”、“任务对话机器人”、“开放闲聊机器人”。但机器人的落地使用过程中,往往需要不同作用的机器人进行结合。
拿电器类客服机器人举例来说,会有如下对话:
用户:“包安装吗”
机器人:”我们是包安装的哦,亲“
以上是我们最常见的问答场景,机器人通过检索方式,找出query对应的answer返回给用不。
再比如:
用户:“我要查物流”
机器人:“您要查询的是哪个订单”(提供订单A&订单B&订单C)
用户:选择A
机器人:该货品目前已经由顺丰发出。
在以上场景中,机器人需要通过多轮方式完成查物流的任务。
这就像咱人一样,在工作中,不仅需要有决策和解决问题的能力,还需要有日常沟通能力,任何一项都是不可或缺的。
由于工作中接触了各类机器人,对于开放域聊天内容的感触比较深的是,闲聊本身在机器人的场景中,作用会相对弱一些,但大部分时候,又属于机器人的基本能力,属于典型的“得不到的永远在骚动,得到的有恃无恐”。
而目前市面上的机器人介绍文档,一方面关于闲聊的内容不多,绝大部分是任务型和检索性的文章;另一方面,闲聊的介绍更偏向于技术实现方式。但小七我认为,想要做好开放域聊天,其实不能只考虑技术实现,而应该从产品本身出发。
所以今天,小七结合之前做开放域机器人的实操过程,主要以儿童机器人场景为例子,从不同角度来阐述如何构建闲聊机器人,跟着我燥起来!
二、吹水的价值
闲聊,俗称“吹水”。朋友间吹水,讲究开心就好。所以,闲聊是一个双方都带有情感诉求的过程,可以是解闷逗乐,也可以是哭诉慰藉。
基于此,如果用户与机器人进行闲聊互动,必定是希望机器人能引起其情感的共鸣和变化。如下对话是用户跟“小爱同学”(小米音箱)的对话:
用户:小爱同学,放个屁
robot:矮油,人家是女孩纸,怎么会做这么羞羞的事情。既然主人想要听放屁,我就勉为其难放一个,放的不好可不许怪我哦。
噗~~
用户在这次对话中,让小爱同学放屁,纯粹是逗乐找趣。同时,机器人的反应也是有一定套路,让用户感受到,这是一个可以给自己带来乐趣的朋友。
当一个朋友情商特别高,能够在自己伤心时给予安慰,无聊时带来乐趣,开心时互相分享,任何一个人都会很感激有这样的益友,让人离不开。
比如用户面前有一个娱乐机器人,前者习惯性会以人与人交流的形式来进行对话。这时候,机器人不能而不是“直男”,顾着解决问题,也应该是一个情商高的朋友,感知用户的情感,并在回复时伴随着相应的情感,让用户感受到乐趣和温度。
只有这样子,用户才能与机器人做更多交互,提高用户粘性,而不是“仰天嘲笑出门去,AI都是智障人”?
三、如何吹水
用户如果有意和机器人扯犊子吹水,必然会有”像人“的期望值。这个标准说起来简单,做起来相当得难,毕竟nlp技术还真没达到完全理解人类的水平。
如果我们换个角度,如《西部世界》中所讲,机器人如果拥有了记忆,便开始进化成有意识的生物了。同样的,对于【像人】(类似有意识)这个状态,我们可以抽象出一些特质,机器人如果拥有了这些特征后,能让用户觉得还不错,愿意聊下去。
那以下是笔者从过往做闲聊机器人过程中所抽象出的特质,下面会一一做介绍。

1. 人设一致性
(1)人设一致性的意义
每个社会人都有自己统一的人设,包括身份、性别、形象、性格、爱好等,人与人之间也是基于这个“本”在对话。即使是路上的陌生人问路,也会先根据对方的形象、性别称呼,比如路上经常有人找我问路,都会说:“你好,帅哥”。而这称呼,本身就是一个人物设定的表现。如果一个人人设不一致,有时候东,有时候西,那要么是这个人太戏精,要么就是神经错乱,比如下面这个人:
A:你是谁
B:我是来自广东的产品经理
A:那你平时工作都在干嘛
B:我在画建筑设计图,敲代码,修空调。
A:(这恐怕是个假的产品经理吧)
机器人也一样,需要立个人设在用户前面,才能让后者有真实感,安全感。如果机器人没有人设,会让聊天变得异常怪异。有时候回答不上来、有时候乱回答,有时候上句不接下句,用户会认为乱七八糟,沟通不了。就如Cathy Pearl在《语言用户界面设计》中所说:“人物模型的一致性,使人们能够在与它们沟通时得以预测接下来会发生什么”。
(2)设计方式
那我们要如何设定机器人的人设呢?平时我们要了解一个人,一般会从其背景信息出发,如名字、家乡、职业、爱好等;其次,通过其谈吐举止,也可以了解一个人的性格特征。
关于机器人的背景,我们需要给到它一个故事。《西部世界》中,每个机器人都有自己的身份和剧本。但用户会问机器人的哪些背景信息呢?事实是,不大可能枚举出一个人的所有背景信息,就连人都可能忘了自己很多以前的事儿。
这里我们可以从日常提问(高频问题)入手。以儿童机器人为例,在我们之前做的项目中,从线上交互数据看出,咨询机器人背景信息的query占了所有交互数据的10%以上。这类问题包括:
- 机器人的身份是什么?姓名、年龄、生日、星座、家乡等
- 机器人的能力是什么?
- 机器人的爱好是什么?
- 机器人的家庭背景、社交背景是怎么样的?
另一方面,我们需要设计机器人的性格特点,以此来体现其谈吐。性格特点可以是风趣、自信、忠诚,亦或是调皮、温暖、腹黑。
最终我们可以有这么一个故事:
我们要创造一个儿童机器人,叫小七,男生,狮子座,关键很帅,来自泰坦星永恒一组,由于星球濒临灭绝,爸爸妈妈送他到了地球,所以他留在地球和人类愉快地生活。小七性格幽默,乐于助人,但有时候也有些腹黑,还有些喜欢掉书袋,教育小朋友。
(3)产品举例
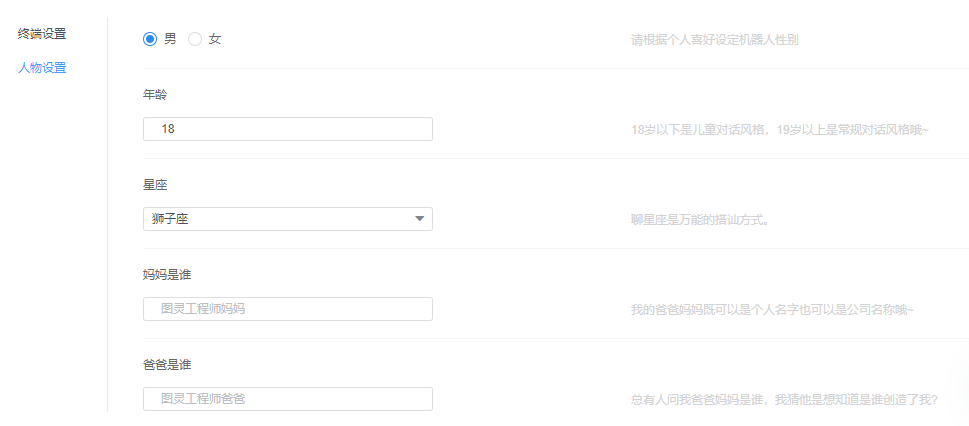
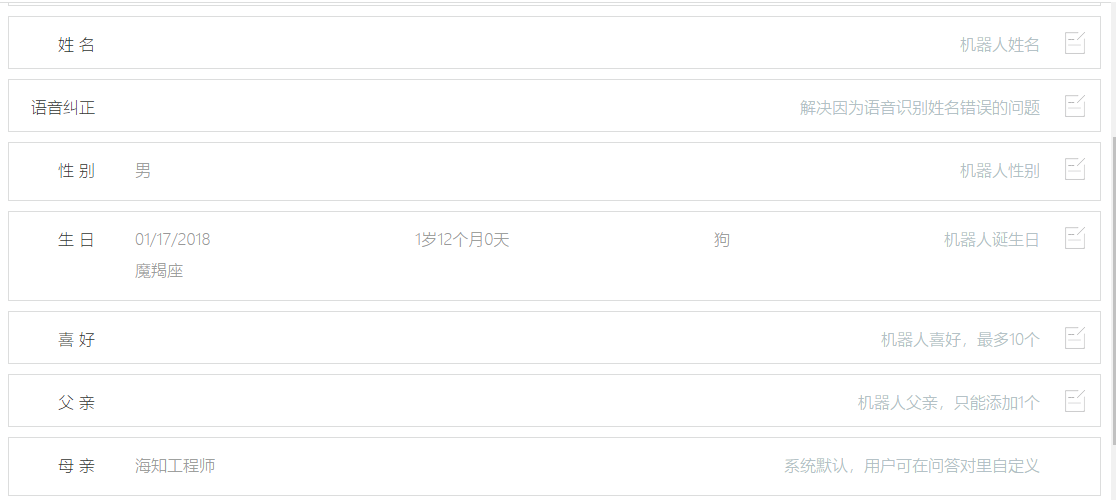
笔者也找了市面上做botframework的平台,这类产品的侧重点主要在于技能定制及模型训练,而对于人设很少涉及。后面发现以下两个平台有相关设定,其中:图灵机器人涉及到的属性有性别、年龄、星座、爸爸妈妈;海知涉及的属性包括姓名、性别、生日、喜好和爸爸妈妈。人设内容不多,但这类机器人基础配置,还是必不可少的。
图灵机器人人设页面:
海知ruyi机器人人设页面:
2. 语言风格设定
(1)意义与设计方式
语言风格首先要符合人设特点。幽默的性格,机器人的回复就需要搞笑轻松一些,若是严谨的性格,机器人说话就需要严肃。想象一下,一个在法院的政务机器人,当你问它你会啥的时候,它说会泡妞撩妹,那场面真的会难以控制。
比如前面提到的小七喜欢掉书袋,那我们可以在小孩子玩游戏很久之后,提醒小朋友需要休息一下,然后看看书,或者引导其来学习古诗词。
确定了语言风格之后,就需要将这种性格特点体现在机器人的对话中。我们可以从用户所有query中,抽象高频场景进行针对性设定,使得机器人人设和说话风格一致,更像一个人在聊天,这也是我们最终的预期效果。
而在这个过程中,为了让机器人显得更加拟人化,我们也尝试加入了一些类似口头禅的feature,比如有的人习惯以“呃”来开始,有的人喜欢说“然后”来衔接。
(2)产品举例
在以往例子中,我们所发现的其中一个高频场景是:用户会重复问同一个问题(不知道是不是都是一些智能程度检验师在聊天,尴尬)。这种情况是极不建议机器人一直是单一回复,那就成了一个对话复读机了。而微软小冰对于用户这种互动,结合了她自己的人设和语言风格来回应(比如:撒娇、傲气)。
我们可以探索下微软小冰的策略:
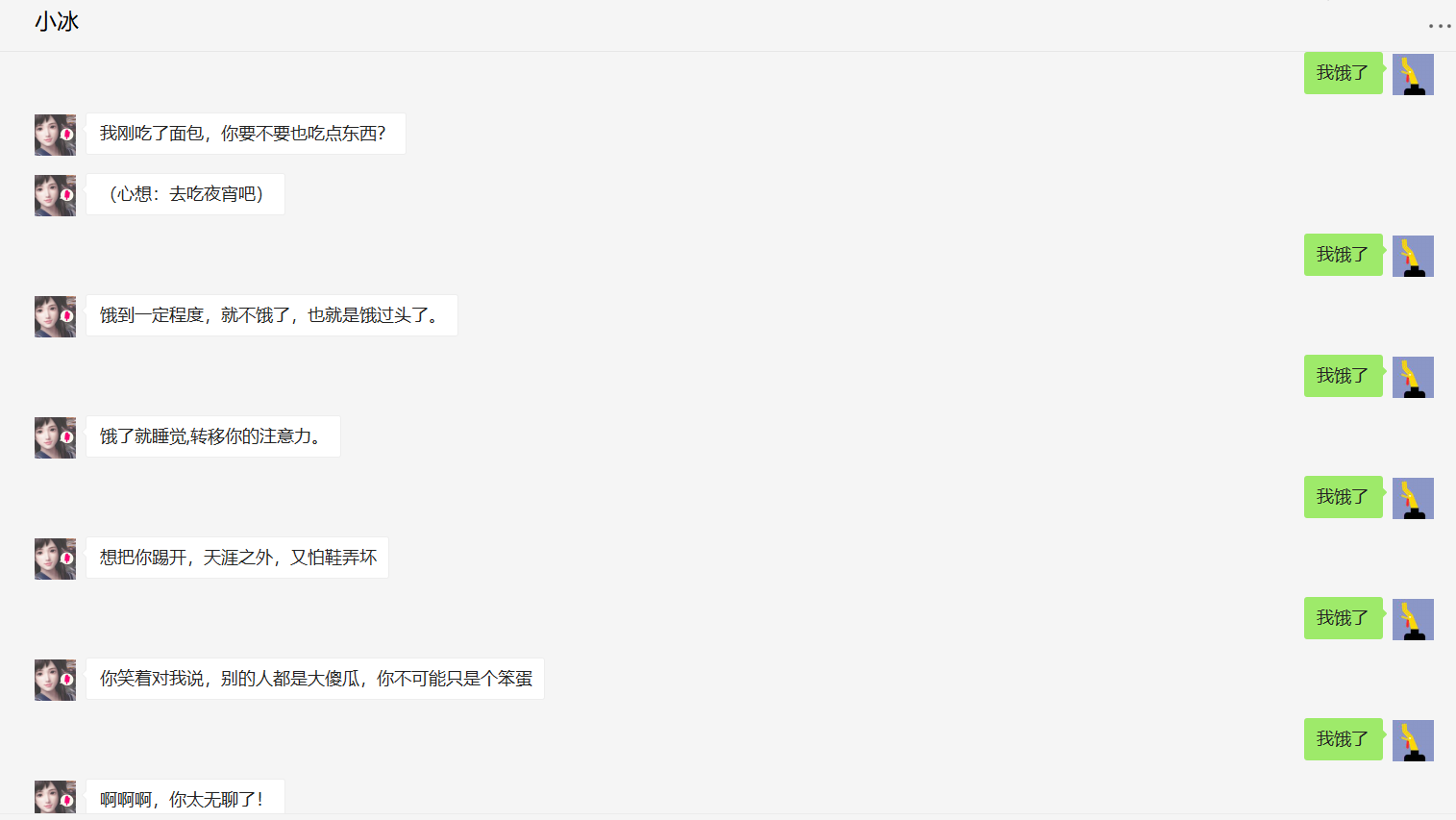
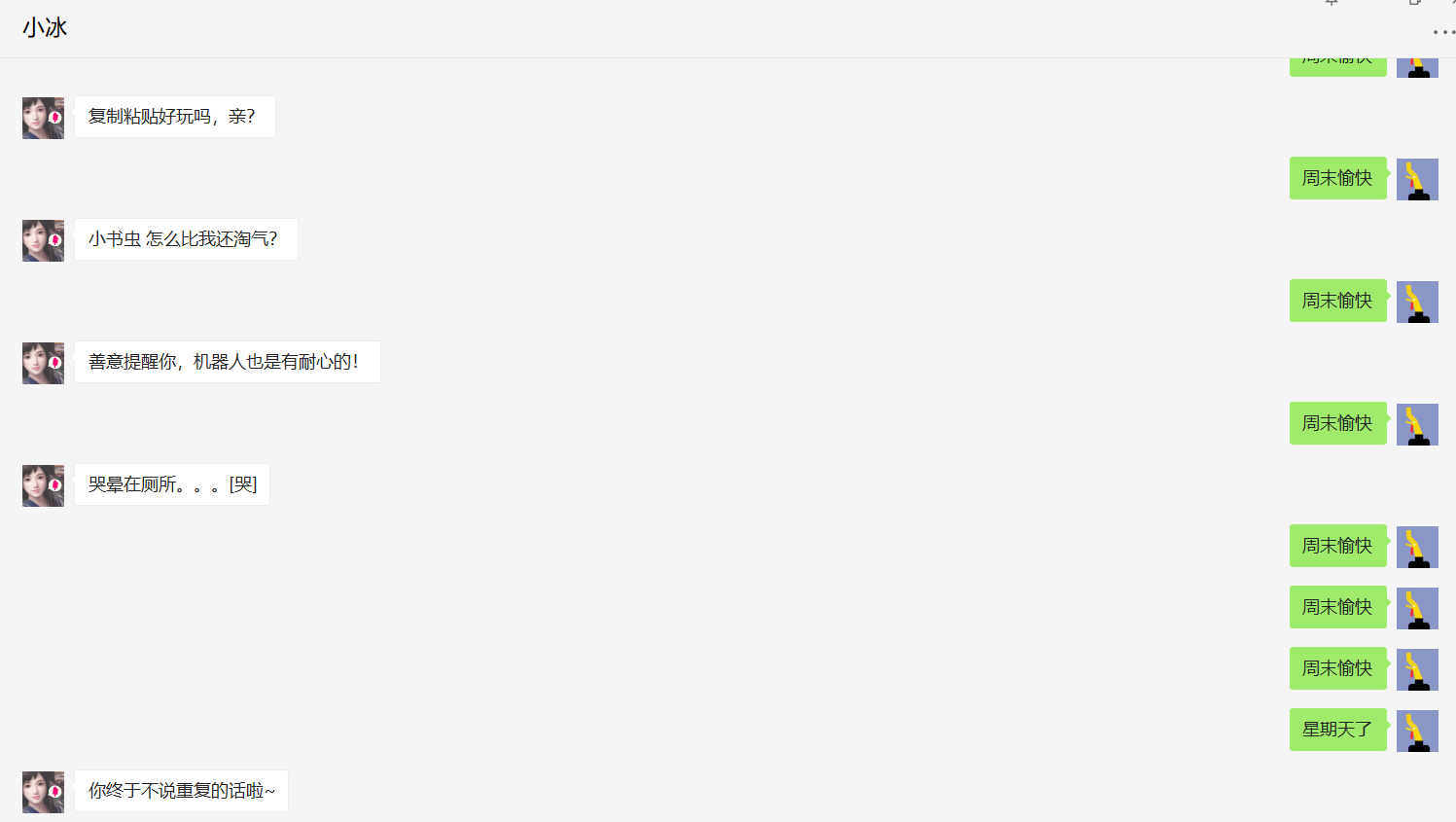
小冰的策略是,针对同个问题,给出不同的回复。若用户重复太多次,小冰会有情绪的变化,慢慢地显得不耐烦,并且开始责怪用户,到最后干脆不回答了,直到用户说其他内容,就回复“你终于不说重复的话啦~”。从中我们可以看出,小冰的语言是很活动调皮并且较为傲娇的。
也只有这样丰富的语言体现,用户才更相信对面是个可以聊天的朋友,而不是一个无聊的智障机器人。
3. 个性化
(1)个性化意义
如同政治课本中的一句话:世界上不会有完全一样的叶子。即使如双胞胎,也会有各自的个性。我们过往发生的每件事情,让我们形成了特有的世界观,价值观,人生观。三观决定了每个人的思想不同,而语言是思想的折射,从而让每个人谈吐都是与众不同的。
相应的,机器人也应该有自己的过往记忆,从而形成自己与众不同的三观。 这样,每个机器人都是个性化的,就跟我们不同性格的朋友一样。
(2)设计方式
当然,如果要记住所有的事情,对于机器人来说是困难的,也会显得没有意义,毕竟人也有记性差的时候。那机器人需要有什么记忆呢?除了刚才的背景信息,最重要的,是要记住它的主人,即用户。
也就是说,机器人需要能记住自己主人相关的信息,包括姓名、性别、爱好等方面,甚至某些过往的交互行为。这样,当某个用户A拥有了一款能记住机子的机器人,即使市面上有其他机器人,对用户来说,这个机器人小伙伴都是独一无二的。
那要记住用户,首先得有个收集用户画像的过程。这各场景就跟男生想要了解妹纸一样,要么是自己主动了解(撩),要么是自己通过细心观察(备胎式方案),被动了解。
1)主动了解型
如果机器人想主动去了解用户,就需要找准时机,否则会显得十分突兀,甚至让用户产生防备心理。
一般来说,最好的时机,应该是两个朋友相互了解的时候。具体我们可以看以下例子:
用户:你叫什么名字呀?
机器人:我叫小七。主人你呢?
用户:我叫小八,你好呀。
机器人:你好,小八。我知道自己主人叫啥了,好开心!
用户:你会做什么呢?
机器人:唱歌跳舞,啥都会呢。小八,你平时喜欢干什么呢?
用户:我也喜欢唱歌呢。
机器人在这样的互动中,能够了解到用户的兴趣爱好,并记忆下来。而用户也会觉得这个机器人真的像自己的玩伴,从而更愿意与其玩下去。
2)细心观察型
当然,如果机器人能够细心留意用户以往说的话,也可以从中了解很多信息,从而做出很惊艳的交互表现。比如:
(早上)
用户:早上好
机器人:早上好,小八。今天周末天气很好,小八有打算去哪里玩吗?
用户:今天要跟爸爸妈妈去动物园。
机器人:听起来很棒呀。要玩得开心哦
(晚上)
用户:晚上好。
机器人:小八呀,今天去动物园玩了一天,能跟我讲讲都玩了什么了吗
用户:我今天看了斑马、狮子、孔雀。。。。
机器人:好像很好玩呀。下次小八带着小七一起去,好不好
机器人不仅能记忆,而且记性也好,让小朋友感觉真的有在关注自己,也让家长相信机器人确实是一个好陪伴,让孩子不会孤单。
通过这样的记忆,让每个机器人都成为特有的存在。每个小朋友都有陪伴自己成长的专属的玩伴。
P.S.当家里有两个小朋友的时候,如果希望机器人能够记住用户是谁,我们也可以通过声纹识别方式记住不同用户的名称。
4. 主动引导
(1)意义
一个相对智能的吹水机器人算是摆在这里了。但事实告诉我们,如果只是这样,用户不会一直和他聊下去。市面上很多机器人会宣称自己有很多能力,可以陪伴小孩子,还可以教小朋友数学、英语等等。咱先不说这些能力有没有用,好不好玩,到底能不能被用户触发,才是首要考虑的问题。
想象一下,两个人在聊天,永远是其中一方在找话题,另一方只是在附和,就算话痨也不可能永远有话题。而且,用户往往不知道要和机器人聊啥,尴尬的气氛会让前者失去聊下去的兴趣。所以,通过机器人主动引导来找话题,从而让用户不断来聊天,便显得尤为重要。
(2)设计方式
设计主动引导的时候,产品经理需要讲究策略,主要解决三个关键点:内容、时机、话术。
1)引导内容
选择引导什么内容,这个取决于机器人的能力和定位,比如一个寓教于乐的机器人,应该多让小朋友做数字游戏、诗词游戏等互动。同时,机器人如果学习(上线)了一些新的能力,也需要及时引导用户来体验,保证用户的活跃度。
2)引导时机
对于时间点的问题,我们可以选择在开头、过程中以及结尾三个timing去触发。
比较常见会在用户唤醒机器人时候去引导其体验能力,如下case便是小度音箱在过年期间的能力引导,会在用户开始闲聊之后,直接推荐响应技能。
user:小度小度,晚上好
小度:晚上好呀。先来看看明天的天气吧,稍后还有精彩节目等着你哦~
小度:明天天气xxxxx
小度:我为您整理了一些收听率很高的节目,听听看吧,觉得不喜欢可以跟我说“换个台”
但如果每次都在唤醒时引导就会显得特别生硬。我们想象一下,两个朋友在扯皮吹水,一般是从一个话题突然想到其他话题就开聊了。同理,用户跟机器人聊天,也应该允许双方聊着聊着就扯到其他话题的。
我们也不必在所有聊天内容中去想办法做话题引导。首先,应该找出用户的高频聊天场景中,比如小朋友会经常让机器人讲笑话,讲完后就可以引导做其他寓教于乐的游戏。当然,实际情况不可能如此简单暴力,触发条件需要做权重计算,包括用户各类技能的触发次数、其他引导场景的触发频率、历史引导的用户反馈(如用户说:我不喜欢)等。
最后就是在结尾的timing做引导,也就是当双方都陷入沉默的尴尬气氛的时候。拿小米音箱举例,由于是全双工唤醒,当用户每隔15s没有说话,则会主动引导一次,连续三次引导无果才会退出唤醒状态。比如:“主人你去哪儿了?告诉你哦,我最近新学了一项技能,要不要跟我一起玩呢”。这样可以引起用户聊下去的兴趣,开始新的话题,保证cps的数据上涨。
3)引导话术
至于最后的引导话术,因为不同场景的话术是不一样的,所以要保证与我们先前讲的语言风格一致,至少不能让一个很严肃的学霸型机器人突然撒娇说:“跟人家聊点别的东东嘛~”
5. 趣味性
所谓好看的皮囊千篇一律,有趣的灵魂万里挑一。说到底,一个chatbot如果不好玩,再怎么折腾也没用。另一方面,聊天机器人始终是一个To C的产品,通过运营好玩的内容,保证活跃和留存是相当重要的。这往往能给到用户意想不到的惊喜,从而产生持续对话的兴趣。
如何让闲聊变得好玩,就不得不提小冰的套路了。一方面,小冰日常会更新技能,不断刺激用户去体验;另一方面,也会在各种聊天中皮一皮,让用户相信这是个有趣的“朋友”,比如上文提到的对于用户故意使坏,一直重复单句的场景。
再比如,小冰曾经更新一个“读心术”的技能,也就是在15个问题之内猜出用户心里想的人物是谁。利用ID3决策树等算法先将人物及特征作为训练样本,再让小冰反问用户,为每个特征分类,最后选中用户的“心上人”。
通过这一个个的小游戏,可以让用户不断产生愉悦感及下次的期待感,朋友之间也是这样,总有一些共同话题和兴趣活动,才能让双方成为知己。
之前设计闲聊机器人时,小七也设定了某些套路策略。比如情人节前后的土味情话,每天用户开始进行互动的时候,以主动消息的方式来发土味情话。当时每天的土味情话在情人节期间还是带来了不少的留存和活跃的。在实现方式上也比较简单,直接利用规则设定即可,ROI还是挺高的。
user:打开聊天女仆
bot:主人你好呀。啊,你有没有闻到什么味道?
user:没有啊/什么味/…
bot:怎么你一出来空气就甜炸了啊
同样的,儿童机器人更需要这样的趣味性和新鲜感,毕竟儿童天性就是“喜新厌旧”。如果小玩伴每天都是玩同样的游戏,说同样的话,到最后一定“没朋友”。所以可以加入寓教于乐的儿童游戏,日常更新的儿童笑话,儿童故事,来吸引小朋友的注意,让孩子喜欢上这个玩伴。
6. 情感
根据马斯洛的需求层次理论,情感和归属(love and belonging)的需要是极为强烈的,缺乏该需求的人,往往会因为没有感受到身边人的关怀,而认为没有价值活在这世界上。而对于开放域聊天机器人,市场往往会将其定位为陪伴,以提供一定程度的情感需求。因此,如何让机器人感知用户的喜怒哀乐并做情感陪伴,就有很大的必要性了。
这里分为两块,其一是如何识别用户情绪;其二是机器人如何做情感反馈。
(1)情绪识别
我们暂不讨论情感识别的技术识别,而是从产品侧分析机器人要识别哪些情绪,从数据角度,就是划分哪些数据作为情感分类。
情感有很多种,态度上有喜欢和讨厌,心情上有悲伤和快乐,人际上有疏远和冷漠,等等。选择哪些情感场景做反馈,主要取决于两点:
- 机器人定位:比如儿童陪伴场景,机器人对用户的大部分情绪都应该有敏感的识别,才能让儿童感受到陪伴的意义;而法律机器人的闲聊场景,很多情感问题可以不用太注重,机器人选择统一回复即可。
- 机器人回复内容的颗粒度:比如在儿童场景中,小朋友骂了脏话,其实不需要了解具体骂的啥内容,都应该先引导小朋友文明用词,所以脏话内容的分类不需要太细,只要是脏话就做统一回复即可。
(2)情感反馈策略
当知道了用户开心、失望还是愤怒的情绪之后,身为“朋友”的机器人就需要有所回应。针对不同的情绪分类,机器人可以有不同的策略。这里我们可以列一下儿童场景中集中回复策略:
用户生气(说脏话):小朋友不可以说脏话哦,这样我就不想跟你玩了,我只想跟文明的小孩做朋友呢~(教育策略)
用户生气(无脏话):怎么了?有人惹你不开心了吗?没事,有小七陪着你舒缓心情呢~不如跟我一起听首好听的儿歌放松放松吧(引导儿童场景)
用户失落:主人,成长路上有不开心的事情,也会有开心的事情呢~至少小七一直陪着主人。对咯,我刚听了一个笑话,可笑死我了,我也让主人开心一下吧~(引导笑话场景)
用户害怕:主人你抱着我,就没啥好怕的了,我们一起变勇敢!
用户开心:主人开心,小七就更开心啦。但是,但是,你要陪小七读诗词的呢,不要忘了哦~(引导诗词场景)
总而言之,机器人的情感陪伴的最终效果,应该是真正做到:不许骗我、骂我,要关心我;别人欺负我时,你要在第一时间出来帮我;我开心时,你要陪我开心;我不开心时,你要哄我开心。嗯,最佳损友!
7. 特别说明:敏感词处理
根据2017年国家颁布的《网络安全法》第47条和68条的规定,企业要保证自己的网络运营平台内容安全,若出现敏感词等违规行为将会收到行政处罚,甚至被勒令停业整改。而作为聊天机器人的产品设计者,需要保证机器人不乱说话,否则牵连成本巨大。
所以一般我们会设计一个敏感词库,并且做日常维护更新。有了敏感词库之后,我们来看机器人的回复语料来源,主要由三种渠道:(1)人工添加;(2)网上爬取;(3)自动生成。对于(1)(2),我们会考虑在录入回复的地方做敏感词过滤;而对于自动生成的回复,一般会在生成回复的时候,过滤掉敏感词。
嗯,做个聪明的机器人,知道什么该说,什么不该说。
四、吹水是怎么练成的
这一章主要聊的是机器人的实现方式,除非是算法类的产品经理,其他AI产品经理的重点还在于用户场景,所以这块我们简单聊一下即可(毕竟说了好多了,在这段感情中累了)。
1. 检索式闲聊实现
基于对话式检索的闲聊主要使用匹配句子相似度的方式,比如先将用户消息及对话库的分类转换为句向量,再计算两者之间的余弦距离以得到语义相似度,最终将相似度最高的分类对应回复话术返回给用户。
想要转换为句向量,由词向量通过监督方法或者无监督方法获得。现在主流的词向量模型有Word2Vec、BERT等。当获得了词向量之后,可以通过各类模型获得,如CNN、跳跃思维向量、快速思维向量。
整体流程可以概括为:
(1)将query做分词等预处理,再通过Word2Vec、BERT等模型将分词结果转化为词向量,再利用快速思维向量、跳跃思维向量等方式获取句向量
(2)将生成的句向量与模型模型已经处理过的分类匹配,计算两者余弦相似度,获得相似度分值;
(3)根据分值排序,选择最佳相似问句,将对应answer返回。
当然,之前算法大大分享过:由于语料库巨大,如果每一条语料都与query计算,匹配效率会贼低。所以可以用一个高效的搜索引擎做粗粒度的筛选,选出候选答案,再进行向量方式处理。
2. 生成式闲聊实现
生成式聊天机器人采用端到端的深度学习模型,如seq2seq,会从海量对话数据中学习到问题和回复,从而对每条query都自动生成回复。翻译过来就是,回复内容不必预设,全部让机器人自己来生成。
一般可以通过LSTM等模型将输入的序列映射为固定长度的向量,然后使用深度LSTM从向量中解码得到目标输出序列。
业界的观点中,目前seq2seq的生成模型往往会出现安全回答的问题、机器人个性不一致的问题和多轮对话中的对话连续性问题。我司算法大大跟我说过,这类情况也不是没办法解决,一般会在生成模型中加入外部知识(如小冰的话题模型以及情感分类模型)来让回复更有意义。
当然,在小七的观点中,生成模型不只是会出现这三个问题,我们刚才讲到的吹水策略,才是闲聊机器人的重点价值体现。生成式虽然可以保证每条消息都能有所答复,但朋友间的闲聊,不在于有话必应,而在于用心沟通,用心交往。
当然,我也曾经天真地设想过一个方案:利用检索式满足策略回复同时,对于大量长尾的query,可以用生成回复,并引用情感等模型来保证回复内容更有意义,这个顾全大局但ROI贼低的方案活生生就被算法大大一句“天真”怼回来了,哈哈哈哈哈~
五、怎么知道吹得好不好
当我们将一个闲聊机器人构建完成并且上线了,不代表产品经理的工作就完成了。我们需要通过数据,了解机器人吹水能力是不是OK的,是不是真的达到用户预期。
平日里我们说一个人沟通能力强,能够和任何人谈笑风生,但并没有一个标准,往往都是主观判断。而机器人是一个产品,产品经理始终需要找到可以衡量价值的指标,才能证明这个闲聊机器人是否真的满足用户需求。
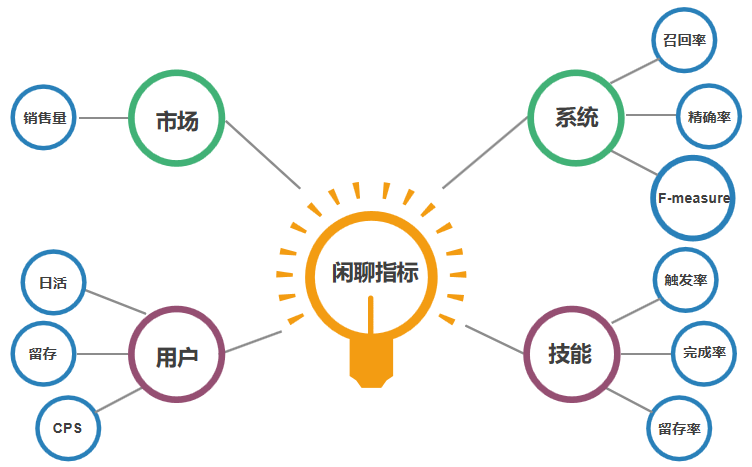
如上图所示,从不同的目标来看,产品经理需要关注不同的指标,比如我们设计了一款儿童陪伴硬件机器人,从上往下都有不同的指标。
对于企业来说,首先关注的就是好不好卖。产品经理就需要根据销售量情况,去设计场景和亮点,保证产品侧对销售量的提升。
从用户角度来说,产品经理就需要关注其使用情况,大部门闲聊场景都是To C,所以避免不了要关注留存、活跃,也只有这两个指标上去了,才能体现机器人陪伴的意义。其次,我们也需要关注每次对话的轮次,来了解用户是否愿意聊下去,也就是业界所说的CPS(单轮对话次数)。
从功能来说,产品经理需要考虑每个技能的使用情况,包括每个技能、场景的触发率、完成率、留存率。这类指标可以说是对整体留存、活跃、CPS的深层次现象探究,比如哪些场景的触发率高,从而提升了cps;哪些技能完成率低,导致整体活跃降低。
最后,机器人是一个智能化系统,自身也应该有一些客观标准来衡量其智能化程度。因为我们讨论的主要是基于检索式的闲聊系统,其常用评判标准有召回率、精准率和F-测度。
本文由 @steseven 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。

时间:2020-03-02 23:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















