“ZAO”凉凉!教你用Deepfakes换脸
近日,一款名为"ZAO"的 AI 换脸软件在社交媒体刷屏,火爆的同时也引发了不少质疑。详情可查看《3天登顶苹果免费榜,“ZAO”作起来会死》
只要在 App 中上传一张照片,你想变成哪个明星,就能变成哪个明星。听起来很梦幻,但却触手可及。
AI 换脸 App“ZAO”零门槛,操作简单……具备走红基因。然而,一夜“爆火”被追捧,一天就“爆雷”被封杀,短短不过 24 小时。



9 月 3 日,ZAO 正式发表道歉声明。ZAO 表示,不会存储个人面部生物识别特征信息,不会产生支付风险,公司非常重视个人信息保护和数据安全。
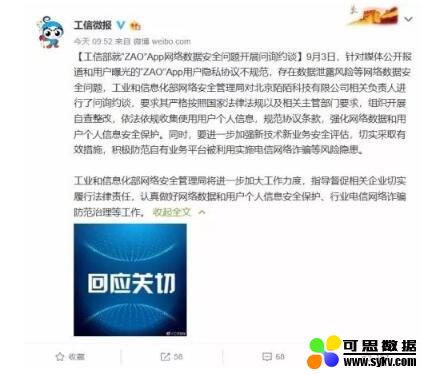
“ZAO”道歉的相关话题很快冲上热搜榜,但由此引发的隐私保护争议和反思并未平息。随后,工信部约谈 ZAO :要求自查整改,依法依规收集使用个人信息!
作为程序员,不会换脸软件怎么能忍?下面教大家徒手使用 Deepfakes 换脸。
如何使用 Deepfakes 换脸?
获取 deepfakes 工具包
- git clone https://github.com/deepfakes/faceswap.git
补齐依赖包:
- pip install tqdm
- pip install cv2
- pip install opencv-contrib-python
- pip install dlib
- pip install keras
- pip install tensorflow
- pip install tensorflow-gpu(如机器带有gpu)
- pip install face_recognition
收集样本
这里我选用的是新垣结衣的样本,费了好半天,下了 100 张图片:
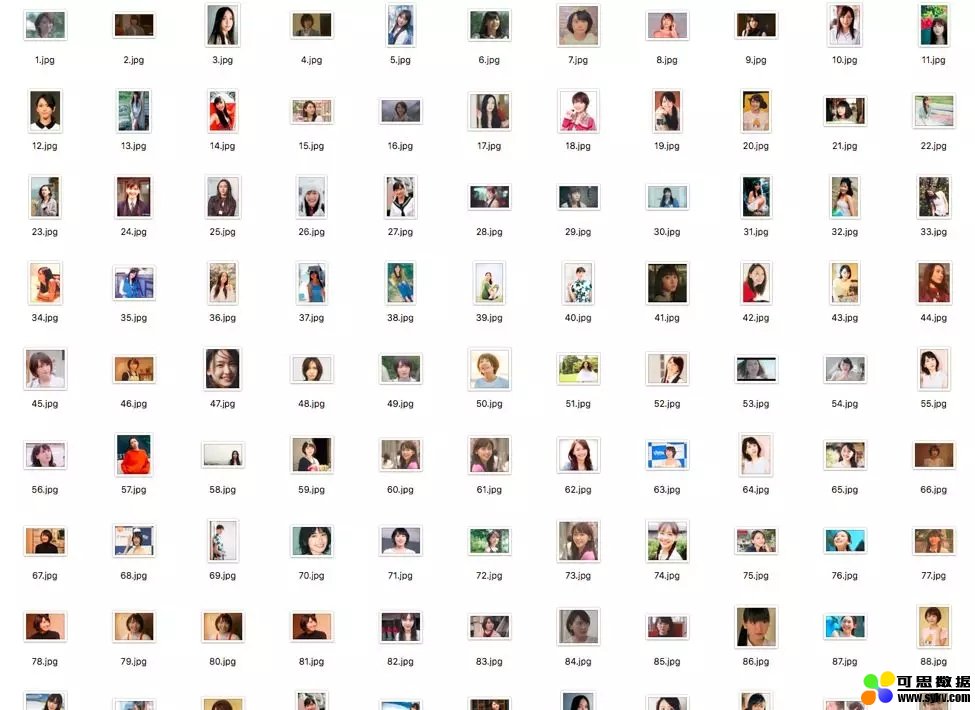
另外一个人的样本是凯瑞穆里根,由于实在是找图片麻烦,所以直接截取了《The Great Gatsby》里的视频,然后用 ffmpeg 转化为图片,大概有 70 张的样子。
面部抓取
在收集完样本后,使用如下命令对样本图片进行面部抓取:
./faceswap.py extract –i input_folder/ –o output_folder/
做这个的原因是因为我们主要关注的是换脸,所以只需要获取脸部的特征,其他环境因素对换脸的影响并不大。

在面部抓取的过程完成后,我们可以得到所有脸部图片。在此,我们可以人工筛选一下不合适的样本(如下图中的 49_1.jpg),将之去除。

面部检测算法 HOG
这里简单提一下脸部特征提取算法 HOG(Histogram of Oriented Gradient)。
严格来说,其实 HOG 是一个特征,是一种在计算机视觉和图像处理中用来进行物体检测的特征描述因子。HOG 特征结合 SVM 分类器已经被广泛应用于图像识别中。
此处脸部检测的一个简单过程如下:
①首先使用黑白来表示一个图片,以此简化这个过程(因为我们并不需要颜色数据来检测一个脸部)。

②然后依次扫描图片上的每一个像素点 。对每个像素点,找到与它直接相邻的像素点。然后找出这个点周围暗度变化的方向。
例如下图所示,这个点周围由明到暗的方向为从左下角到右上角,所以它的梯度方向为如下箭头所示:

③在上一个步骤完成后,一个图片里所有的像素点均可由一个对应的梯度表示。这些箭头表示了整个图片里由明到暗的一个趋势。
如果我们直接分析这些像素点(也就是按色彩的方式分析),那么那些非常亮的点和非常暗的点,它们的值(RGB 值)肯定有非常大的差别。
但是因为我们在这只关注明亮度改变的方向,所以由有色图和黑白图最终得到的结果都是一样的,这样可以极大简化问题解决的过程。

④但是保存所有这些梯度会是一个较为消耗存储的过程,所以我们将整个图片分成多个小方块,并且计算里面有多少不同的梯度。
然后我们使用相同梯度最多的方向来表示这个小方块的梯度方向。这样可以将原图片转化为一个非常简单的表现方式,并以一种较简单的方法抓取到面部的基本结构。

⑤当计算到一个图片的 HOG 特征后,可以使用这个特征来对通过训练大量图片得出的 HOG 特征进行比对。如果相似度超过某个阈值,则认为面部被检测到。

开始训练
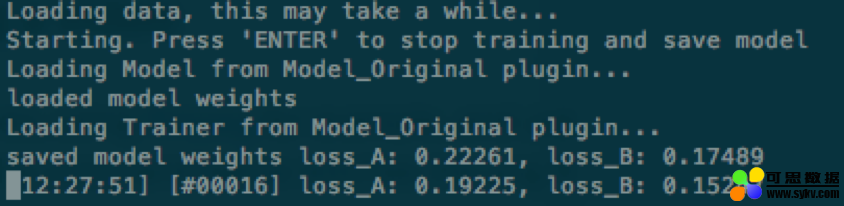
在提取两个人脸的面部信息后,直接使用下面命令开始进行模型的训练:
- ./faceswap.py train -A faceA_folder/ -B faceB_folder -m models/
其中 -m 指定被保存的 Models 所在的文件夹。也可以在命令里加上 -p 参数开启 Preview 模式。
在训练过程中,可以随时键入 Enter 停止训练,模型会保存在目标文件夹。
训练使用的深度学习框架是 Tensorflow,它提供了保存 Checkpoint 的机制(当然代码里必须用上)。
在停止训练后,以后也可以随时使用上面的命令读取之前训练得出的权重参数,并继续训练。
转换人脸
在训练完模型后(损失值较低),可以使用以下命令对目标图进行换脸:
- ./faceswap.py –i input_images_folder/ -o output_images_folder/ -m models/
此处的例子是找的一个视频,所以我们可以先用下面的命令将一个视频以一个固定频率转化为图片:
- ffmpeg –i video.mp4 output/video-frame-%d.png
然后执行转换人脸操作。最后将转换后的人脸图片集合,合成一个视频:
- ffmpeg –i video-frame-%0d.png -c:v libx264 -vf “fps=25, format=yuv420p” out.mp4
下面是两个换脸图(样本 A,110 张图片;样本 B,70 张图片,训练时间 6 小时):


嗯…效果不咋样… 建议大家可以增大样本量,并延长训练时间。
转换人脸的过程
下面简单的聊一下转换人脸的过程。这里用到了 AutoEncoder(一种卷积神经网络),它会根据输入图片,重构这个图片(也就是根据这个图片再生成这个图片):
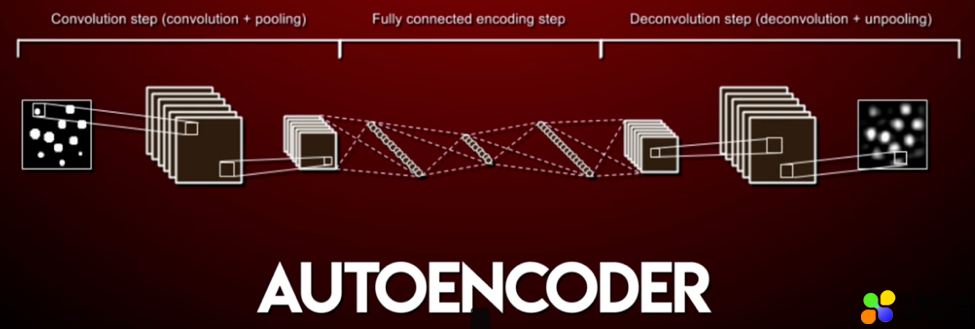
这里 AutoEncoder 模型做的是:首先使用 Encoder 将一个图片进行处理(卷积神经网络抽取特征),以一种压缩的方式来表示这个图片。然后 Decoder 将这个图片还原。
具体在 Deepfakes 中,它用了一个 Encoder 和两个 Decoder。在训练的部分,其实它训练了两个神经网络,两个神经网络都共用一个 Encoder,但是均有不同的 Decoder。
首先 Encoder 将一个图片转化为面部特征(通过卷积神经网络抽取面部的细节特征)。然后 Decoder 通过这个面部特征数据,将图片还原。
这里有一个 error function(loss function)来判断这个转换的好坏程度,模型训练的过程就是最小化这个 loss function(value)的过程。
第一个网络只训练图片 A,第二个网络只训练图片 B。Encoder 学习如何将一个图片转化为面部特征值。
Decoder A 用于学习如何通过面部特征值重构图片 A,Decoder B 用于学习如何通过面部特征值重构图片 B。
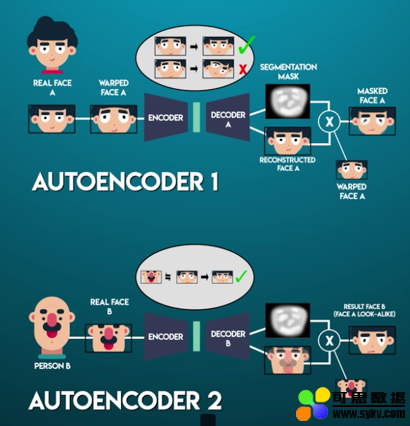

所以在训练时,我们会将两个图片均送入同一个 Encoder,但是用两个不同的 Decoder 还原图片。
这样最后我们用图片 B 获取到的脸,使用 Encoder 抽取特征,再使用 A 的 Decoder 还原,便会得到 A 的脸,B 的表情。

时间:2019-09-08 21:37 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关推荐:
网友评论:















