浪潮开源发布全球首个完整方案的FPGA高效AI计算
8月28日在北京举行的2019人工智能计算大会(AICC2019)上,浪潮宣布开源发布基于FPGA的高效AI计算框架TF2,这一框架的推理引擎采用全球首创的DNN移位计算技术,结合多项最新优化技术,可实现通用深度学习模型基于FPGA芯片的高性能低延迟部署,这也是全球首个包含从模型裁剪、压缩、量化到通用模型实现等优化算法的完整方案的FPGA上AI开源框架,项目开源网址为https://github.com/TF2-Engine/TF2。据悉目前已有快手、上海大学、华大智造、远鉴科技、睿视智觉、华展汇元等多家公司或研究机构加入TF2开源社区,社区将共同推动基于可定制芯片FPGA的AI技术的开源开放合作发展,降低高性能AI计算技术门槛,帮助AI用户和开发者缩短开发周期。
当前,可定制、低延迟、高性能功耗比的FPGA技术成为很多AI用户部署推理应用的选择,但FPGA开发难度大、周期长,难以适应快速迭代的深度学习算法应用需求。TF2可快速实现基于主流AI训练软件和深度神经网络模型DNN的FPGA线上推理,帮助用户最大限度的发挥FPGA计算能力,实现FPGA的高性能、低延迟部署。同时TF2计算架构也可以快速实现AI芯片级设计和性能验证。
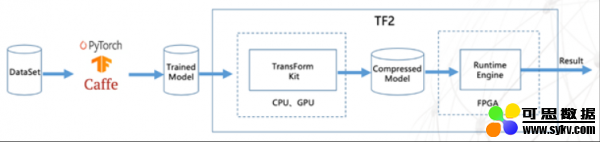
TF2计算加速流程
TF2由两部分组成。第一部分是模型优化转换工具TF2 Transform Kit,可将经过PyTorch、TensorFlow、Caffe等框架训练得到的网络模型数据进行压缩、裁剪、8位量化等操作,减少模型计算量。如对于ResNet50模型,通过压缩32位浮点模型为4位整数模型、通道裁剪,可将模型文件裁剪掉93.75%,几乎无精度损失并保持原始模型的基本计算架构。第二部分是FPGA智能运行引擎TF2 Runtime Engine,可将已优化转换的模型文件自动转化为FPGA目标运行文件,通过创新的DNN移位计算技术大幅提升FPGA做推理计算的性能,并有效降低其实际运行功耗。TF2已完成在ResNet50、FaceNet、GoogLeNet、SqueezeNet等主流DNN模型上的测试验证。在浪潮F10A FPGA卡上采用FaceNet模型对TF2进行的测试(BatchSize=1)表明,运行TF2后单张图片的计算耗时为0.612ms,提速12.8倍。
同时,浪潮开源的项目中还包括TF2的软件定义的可重构芯片设计架构。此架构完整支持当前CNN网络模型的开发,并可快速移植使其支持Transformer、LSTM等网络模型开发。以此架构为基础,可进一步实现ASIC芯片开发原型设计。
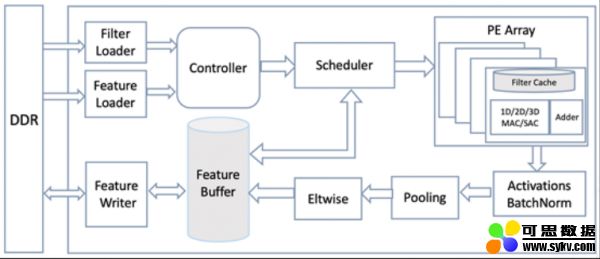
开源的FPGA芯片级设计
根据浪潮公布的开源社区建设计划,浪潮将持续投入对TF2进行更新,将开发开源自动模型解析、结构性裁剪、任意比特量化、基于AutoML的裁剪和量化等新功能,支持稀疏计算、Transformer网络模型、NLP通用模型等。此外,社区将定期举行开发者会议和线上公开课,分享最新技术进展和经验成果,并通过高校教育计划培养开发者,同时开展用户移植方案制定和开发技术支持。
浪潮集团AI&HPC总经理刘军表示:“AI应用部署涵盖云端、边端、移动端,需求非常多样,TF2可极大提升跨端应用部署的效率,快速适应不同场景下模型推理需求。欢迎广大AI用户和开发者加入TF2开源社区,共同加速AI应用部署,推动更多AI应用落地。”
浪潮是人工智能计算的领导品牌,AI服务器中国市场份额保持50%以上,并与人工智能领先科技公司保持在系统与应用方面的深入紧密合作,帮助AI客户在语音、语义、图像、视频、搜索、网络等方面取得数量级的应用性能提升。浪潮与合作伙伴共建元脑生态,共享AI计算、资源与算法三大核心平台能力,助力行业用户开发并部署属于自己的“行业大脑”,加速推进产业AI化落地。

时间:2019-09-07 17:01 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















