从大数据到 AI:AI 的现状和未来
事实证明,从大数据到数据分析再到 AI 的转变是一个很自然的过程。这不仅是因为这个过程有助于调整人类的思维模型,或者因为大数据和数据分析在被 AI 夺去光彩之前浸淫在 AI 的各种炒作中,主要还是因为我们需要通过大数据来构建 AI。

AI 走向主流只用了几年时间,尽管在很多方面已经取得了快速进展,但真正了解 AI 的人并不多,能够掌握 AI 的人就更少了。
2016 年,AI 炒作刚刚开始,很多人在提到“AI”一词时仍然十分谨慎。毕竟,多年来我们一直被灌输要尽量避免使用这个术语,因为这些事情已经引起了混乱,它们承诺过度,却无法兑现。事实证明,从大数据到数据分析再到 AI 的转变是一个很自然的过程。
这不仅是因为这个过程有助于调整人类的思维模型,或者因为大数据和数据分析在被 AI 夺去光彩之前浸淫在 AI 的各种炒作中,主要还是因为我们需要通过大数据来构建 AI。
让我们回顾一下 Big Data Spain(BDS)大会,它是欧洲最大和最具前瞻性的大会之一,标志着从大数据到 AI 的转变,并尝试回答一些与 AI 相关的问题。
在真正成功之前,我们能先假装成功吗?
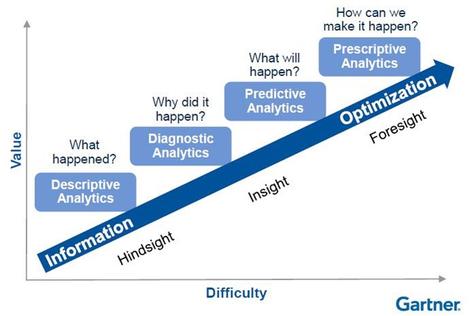
简单地说:不行。Gartner 分析成熟度模型的一个要点是,如果你想构建 AI 功能,就必须在可靠的大数据基础上进行。
其中一部分是关于存储和处理大量数据的能力,但这真的只是冰山一角。现在的技术解决方案已经琳琅满目,但要构建 AI,你不能忘了人和流程。
更具体地说:不要忘了组织中的数据素养和数据治理。如果你认为可以通过某种方式跨过数据分析的演化链在你的组织中开发 AI 解决方案,那么请三思。
Stratio 首席执行官 Oscar Mendez 在他的主题演讲中强调,要超越华而不实的 AI,需要采取整体方法。做好数据基础设施和数据治理,并在此基础上训练正确的机器学习(ML)模型,这样可以获得令人印象深刻的结果。但这些可以带给你的好处是有限的,Alexa、Cortana 和 Siri 的日常失误足以证明这一点。
关键是要具备上下文和推理能力,以便更接近地模拟人类智能。并不是 Mendez 一个人这么认为,因为这也是 AI 研究人员同样持有的观点,例如深度学习领域顶级的思想家之一 Yoshua Bengio。深度学习(DL)在模式匹配方面表现优异,数据和计算能力的爆发让它在基于模式匹配的任务中胜过人类。
然而,智能并非只是关于模式匹配。推理能力不能只通过 ML 方法来建立——至少现在不行。因此,我们需要整合远离炒作的 AI 方法:知识表示和推理、本体论等。这是我们一直在倡导的,并且看到了它在 BDS 上很受推崇,这是一种正面的肯定。
应该将 AI 外包吗?
简单地说:也许可以,但应该要十分谨慎。我们可以直截了当地说:AI 其实很难。是的,AI 绝对应该建立在数据治理的基础之上,因为这无论如何对你的组织来说都是有好处的。有些组织,比如 Telefonica,通过执行战略计划设法从大数据转向 AI,但这并非易事。
这一点已经被一份相当可靠的 ML 采用调查报告所证实,超过 1 万 1 千多个受访者参与了这次调查。来自 Derwen 的 Paco Nathan 展示了 O’Reilly 的一份调查的结果,这或多或少地证实了我们的想法:采用 AI 和没有采用 AI 的组织之间的差距越来越大。
在 AI 采用频谱的一边是谷歌和微软这样的领导者:他们将 AI 作为其战略和运营的核心要素。他们的资源、数据和技术成为他们领导 AI 竞赛的先决条件。然后是 AI 采用者,他们在自己的领域中应用 AI。然后是落后者,他们陷于技术债务之中,无法在 AI 采用方面做出任何有意义的事情。

从表面上看,AI 领导者提供的产品似乎是在普及“AI”。谷歌和微软都在 BDS 上展示了这些,他们做了一些演示,在几分钟内通过点击的方式就构建出一个图像识别应用程序。
很明显,他们在向我们传达这样的一个信息:让我们来操心模型和培训的事,你只要专注在你领域内的细节上。我们可以识别机械部件——只需要提供给我们特定的机械部件就可以了,然后你该干什么干什么去。
谷歌还在 BDS 上发布了一些新产品:Kubeflow 和 AI Hub。它们背后的想法是编排 ML 管道,类似于 Kubernetes 为 Docker 容器提供的应用程序。这些并不是唯一能够带来类似优势的产品。它们看起来有点诱人,但你应该使用它们吗?
谁不想直接跳过 AI 这道坎,拿到想要的结果,而且不需要面对那么多麻烦?这确实是一种可以让你领先于竞争对手的方法。但问题是,如果你完全将 AI 外包,那么你就无法获得在中长期内自给自足所需的技能。
想想数字化转型。是的,数字化、探索技术和重新设计流程也是很难的。并非所有组织都能做到,或者有能力投入足够的资源,但那些做到的组织现在已经跑在了前面。AI 具有类似甚至更大的颠覆潜力。因此,可以立即获得成果固然好,但 AI 的投资仍然应该被视为战略的重点。
当然,你可以考虑外包基础设施。对于大多数组织而言,维护自己的基础设施的数量并未增加。在云端运行基础设施所带来的规模经济性和领先优势将带来实质性好处。
我们将去向何处?
简单地说:就像登月一样。ML 反馈闭环似乎正在全面展开,因此,采用者试图跟上,落后者保持滞后,但领导者却越来越领先。
Pablo Carrier 在演讲指出,如果你尝试线性提高 DL 的准确率,计算量将呈指数级增长。在过去六年中,计算量增加了 1000 万倍。即使是谷歌云也很难跟上,更不用说其他的了。
Google Cloud AI 技术主管 Viacheslav Kovalevskyi 在开始他的“分布式 DL 理论和实践”演讲之前,警告说:如果有可能,请避免使用它。如果你真的必须这么做,请注意与分布式相关的开销,并准备在计算和复杂性以及基础账单方面付出代价。
Kovalevskyi 提供了一些不同的使用分布式 DL 的历史视角——分布数据、模型或二者。分布数据是最简单的方法,分布两者是最难的。但是,无论如何,分布式 DL 仍然是一个“童话之地”——通过增加 k 倍计算时间,你并不会获得 k 倍的性能提升。
当然,Google 的演示主要关注 Google Cloud 上的 TensorFlow,但这不是唯一可用的方法。Databricks 刚刚宣布支持 HorovodRunner,通过 Horovod 来辅助分布式 DL。Horovod 是一个开源框架,由 Uber 推出,谷歌也在使用它。
微软数据科学家和 Azure 数据 /AI 技术专家 Marck Vaisman 在他的演讲中提出了替代方案,他使用了 Python 和 R,而不使用 Spark。他介绍了 Dask,一个 Python 开源库。Dask 承诺为分析提供高级并行性,可以与 Numpy、Pandas 和 Scikit-Learn 等项目协同工作。
最后,图和图数据库也是整个 BDS 的关键主题:微软的知识图、AWS Neptune 和 Oracle Labs。
云计算、分发式以及在 ML 中引入图结构是未来需要关注的一些关键主题。
英文原文:https://www.zdnet.com/article/from-big-data-to-ai-where-are-we-now-and-what-is-the-road-forward/

时间:2019-01-31 23:53 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















