人脸识别哪家强?亚马逊、微软、谷歌等大公司

哪一个人脸识别 API 是最好的?让我们看看亚马逊的 Rekognition、谷歌云 Vision API、IBM 沃森 Visual Recognition 和 微软 Face API。
Part 1:基于互联网提供软件服务的供应商
TLDR:如果你想尽可能快的使用 API,可以直接查看我在 Github 上的代码。
你曾经有过人脸识别的需要吗?
可能只是为了提高图片裁剪成功率,保证一张轮廓图片真实的包含一张人脸,或可能只是简单从你的数据集中发现包含指定人物的图片(在这种情况下)。
哪一个人脸识别软件服务供应商对你的项目来说是最好的呢?
让我们深入了解它们在成功率,定价和速度方面的差异。
在这篇文章里,我将会分析以下人脸检测 API:
-
亚马逊 Rekognition
-
谷歌云 Vision API
-
IBM 沃森 Visual Recognition
-
微软 Face API
人脸检测是如何工作的?
在我们深入分析不同的解决方案之前,让我们首先了解下人脸检测是如何工作的。
Viola–Jones 人脸检测
2001 年这一年,Jimmy Wales 和 Larry Sanger 建立了维基百科,荷兰成为世界上第一个将同性婚姻合法化的国家,世界也见证了有史以来最悲惨的恐怖袭击之一。
与此同时,两位聪颖的人,Paul Viola 和 Michael Jone,一起开始了计算机视觉的革命。
直到 2001 年,人脸检测还不是很精确也不是很快。而就在这一年,Viola Jones 人脸检测框架被提出,它不仅在检测人脸方面有很高的成功率,而且还可以进行实时检测。
虽然人脸和物体识别挑战自 90 年代以来就一直存在,但在 Viola - Jones 论文发布后,人脸及物体识别变得更加繁荣。
深度卷积神经网络
其中一个挑战是自 2010 年以来一直举办的 ImageNet 大规模视觉识别挑战。在前两年,顶级团队主要是通过 Fisher 向量机和支持向量机的组合工作,而 2012 年这一切改变了。
多伦多大学的团队(由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 组成)首次使用深度卷积神经网络进行物体检测。他们以 15.4 % 的错误率获得第一名,而第二名队伍的错误率却高达 26.2 %!
一年后,2013 年,前五名的每个团队都在使用深度卷积神经网络。
那么,这样的网络是如何工作的呢?
今年早些时候,谷歌发布了一个易于理解的视频:
亚马逊、谷歌、IBM 和微软现在使用着什么?
从那以后,并没有太大变化。今天的供应商仍然使用深度卷积神经网络,当然可能会与其他深度学习技术相结合。
显然,他们没有公布自己的视觉识别技术是如何工作的。我发现的信息是:
-
亚马逊:深度神经网络
-
谷歌: 卷积神经网络
-
IBM: 深度学习算法
-
微软: 人脸算法
虽然它们听起来都很相似,但结果有一些不同。
在我们测试它们之前,让我们先看看定价模型吧!
定价
亚马逊、谷歌和微软都有类似的定价模式,这意味着随着使用量的增加,每次检测的价格会下降。
然而,对于 IBM,在你的免费层使用量用完之后,你就要为每次调用 API 支付相同的价格。
Microsoft 为你提供了最好的免费协议,允许你每月免费处理 30000 张图片。
如果你需要检测更多,则需要使用他们的标准协议,是从第一张图片开始付费的。
价格比较
话虽如此,让我们计算三种不同配置类型的成本。
-
条件 A:小型初创公司/企业可每月处理 1000 张图片
-
条件 B:拥有大量图像的数字供应商,每月可处理 100,000 幅图像
-
条件 C:数据中心每月处理 10,000,000 张图像。

从数据上看,对于小客户来说,定价没有多大差别。虽然亚马逊从第一张图片开始收费,但处理 1000 张图片仍然只需要一美元。然而,如果你不想支付任何费用,那么谷歌、IBM 或微软将是你想要选择的供应商。
注意:亚马逊提供了免费协议,你可以免费处理前 12 个月,每月 5000 张图片!然而,在这个 12 个月的试用期后,你就需要从这时第一张图片付费了。
大量使用 API 的情况
如果你确实需要处理数百万张图片,那么比较每个供应商的处理规模就变得很重要了。
以下是在一定数量的图片后,为 API 使用支付的最低价格列表。
-
IBM 会不断向你收取每 1,000 张图片 4.00 美元的费用(无缩放比例)
-
Google 在第 5,000,000 张图片之后,价格降到 0.60 美元(每 1000 张图片)
-
亚马逊会在第 100,000,000 张图片之后,价格降到 0.40 美元(每 1000 张图片)
-
微软会在第 100 ' 000 ' 000 张图片之后,价格降到 0.40 美元(每 1000 张图片)
因此,比较价格,微软(和亚马逊)似乎是赢家。但他们能否在成功率、速度和整合度上占优么?让我们看一看!
设置我们的图像数据集
首先要做的事,在我们扫描人脸图像之前,让我们设置图像数据集。
在这篇博客文章中,我已经从 pexels.com 下载了 33 张图片,非常感谢图片的贡献者/摄影师以及感谢 Pexels!
这些图像已经提交到了 GitHub 存储库,所以如果你只想开始使用 API,则不需要搜索任何图像。
编写基本测试框架
框架可能是错误的,因为我的自定义代码只包含两个类。然而,这两个类帮助我轻松地分析图像(元数据)数据,并在不同的实现中有尽可能少的代码。
一个非常简短的描述:FaceDetectionClient 类保存有关图像存储位置、供应商详细信息和所有处理过的图像(作为 FaceDetectionImage 对象)的一般信息。
比较供应商的 SDK
因为我最熟悉 PHP,所以我决定在这次测试中坚持使用 PHP。我想指出每个供应商提供了什么样的 SDK(截至今天):
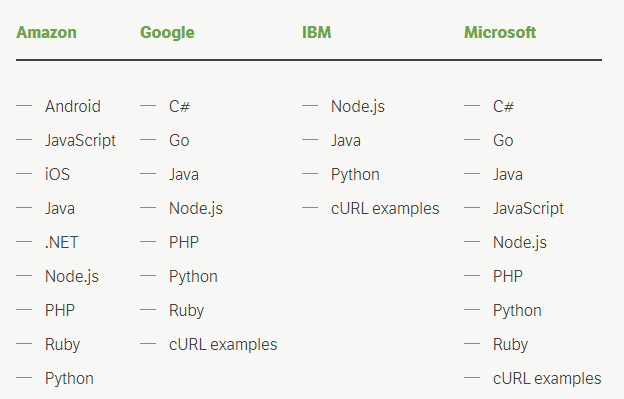
注意:微软实际上并没有提供任何 SDK,但他们为上面列出的技术提供了代码示例。
如果你仔细阅读了这些列表,你可能会注意到 IBM 不仅提供了最少数量的 SDK,而且还没有提供针对 PHP 的 SDK。然而,这对于我来说并不是一个大问题,因为他们提供了 cURL 示例,这些示例帮助我轻松地为一个(非常基本的)IBM 视觉识别客户端类编写了 37 行代码。
集成供应商的 API
获取 SDK 非常容易。使用 Composer 更容易。然而,我确实注意到一些可以改进的东西,以便开发者的生活变得更轻松。
亚马逊
我从亚马逊的识别 API 开始。浏览他们的文档后,我真的开始觉得有点失落。我不仅没找到一些基本的例子(或者无法找到它们?),但我也有一种感觉,我必须点击几次,才能找到我想要的东西。有一次,我甚至放弃了,只是通过直接检查他们的 SDK 源代码来获得信息。
另一方面,这可能只发生在我身上?让我知道亚马逊的识别对你来说是容易(还是困难)整合的吧!
注意:当 Google 和 IBM 返回边界框坐标时,Amazon 会返回坐标作为整体图像宽度/高度的比率。我不知道为什么,但这没什么大不了的。你可以编写一个辅助函数来从比率中获取坐标,就像我一样。
谷歌
接下来是谷歌。与亚马逊相比,他们确实提供了一些例子,这对我帮助很大!或者也许我已经处于投资不同 SDK的心态了。
不管情况如何,集成 SDK 感觉要简单得多,而且我可以花费更少的点击次数来检索我想要的信息。
IBM
如前所述,IBM(还没有?)为 PHP 提供一个 SDK。然而,通过提供的 cURL 示例,我很快就建立了一个自定义客户端。如果已经能提供一个 cURL 例子,那么你使用它也错不了什么了。
微软
看着微软的 PHP 代码示例(使用 Pear 的 HTTP _ request2 包),我最终为微软的 Face API 编写了自己的客户端。
我想我只是一个 cRUL 人。
评估者的可靠性
在我们比较不同的人脸检测 API 之前,让我们先自己扫描图像吧!一个普通的人能检测到多少张脸?
如果你已经看过我的数据集,你可能已经看到了一些包含棘手面孔的图像。棘手是什么意思?好吧,指的是只看到一张脸的一小部分或这张脸处于一个不寻常的角度时。
是时候做一个小实验了
我浏览了所有的图片,记下了我认为已经检测到的面孔数量。我会用这个数字来计算每个供应商对图片的成功率,看看它是否能检测到像我一样多的面孔。
然而,设置仅由我单独检测到的预期面部数量对我来说似乎有点太偏颇了。我需要更多的意见。这时,我恳请我的三位同事浏览我的照片,并告诉我他们会发现多少张脸。我给他们的唯一任务是告诉我你能探测到多少张脸,而不是头。我没有定义任何规则,我想给他们任何可以想象的自由来完成这项任务。
什么是脸?
当我浏览图像检测面部时,我只计算了至少四分之一左右可见的每张脸。有趣的是,我的同事提出了一个略微不同的面部定义。
-
同事 1:我也计算过我大多无法看到的面孔。但我确实看到了身体,所以我的脑海里告诉我有一张脸。
-
同事 2:如果我能够看到眼睛,鼻子和嘴巴,我会把它算作一张脸。
-
同事 3:我只计算了能够在另一张图像中再次识别的脸部。
样例图片 #267855

在这张照片中,我和我的同事分别检测到了 10、13、16 和 16 张面孔。我决定取平均值,因此得到了 14。我对每个人是如何想到不同的人脸检测技术这一点非常的感兴趣。
话虽如此,我还是使用了我和同事的平均人脸计数来设定一幅图像中检测到的预期人脸数量。
结果比较
现在我们已经设置了数据集和代码,让我们处理所有竞争对手的所有图像并比较结果。
我的 FaceDetectionClient 类还附带一个方便的 CSV 导出格式,它提供了一些分析数据。
这是我得到的结果:
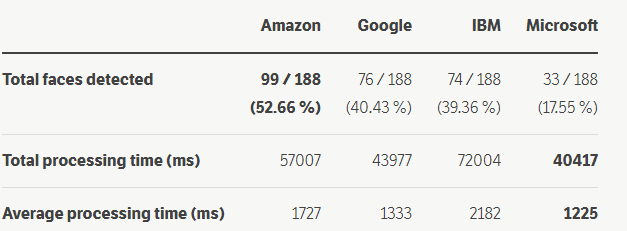
成功率很低?
亚马逊能够检测到 52.66 % 的人脸,谷歌 40.43 %,IBM 39.36 %,微软甚至只有 17.55 %。
为什么成功率低?首先,我的数据集中确实有很多棘手的图像。其次,我们不应该忘记,作为人类,我们有着两百万年的进化背景来帮助理解什么是什么。
虽然许多人认为我们已经掌握了科技领域的人脸检测,但仍有改进的余地!
对速度的需求
虽然亚马逊能够检测到最多的人脸,但谷歌和微软的处理速度明显快于其他公司。然而平均来说,他们仍然需要超过一秒钟的时间来处理我们数据集上的单个图像。
将图像数据从我们的计算机/服务器发送到另一台服务器肯定也会影响性能。
注意:我们将在本系列的下一部分中了解(本地)开源库是否可以更快地完成同样的工作。
(相对)小脸的人群
在分析了这些图像后,亚马逊似乎非常擅长检测人群中的人脸,以及相对较小的脸部。
小摘录
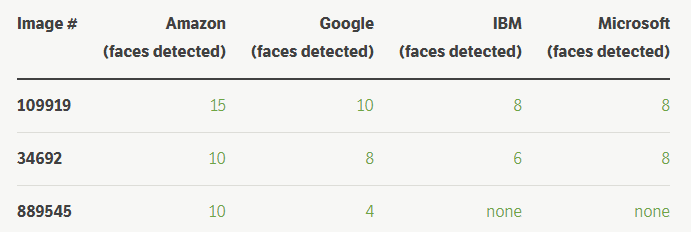
亚马逊的示例图像 # 889545
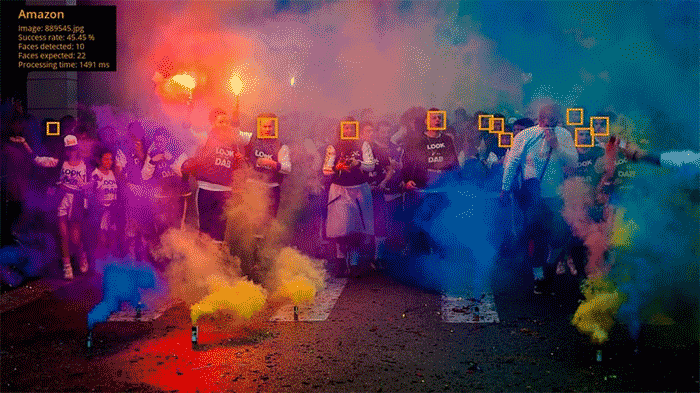
亚马逊能够在这张图片中检测到 10 张面孔,而谷歌只发现了 4 张,IBM 检测到 0 张以及微软检测到 0 张。
不同的角度,不完整的脸
那么,这是否意味着 IBM 根本不如他竞争对手好呢?一点也不。虽然亚马逊可能擅长于在集体照片中检测小脸,但 IBM 还有另一个优势:困难的图像。这是什么意思呢?好吧,指的是头部处于不寻常角度或者可能没有完全显示的脸部图像。
以下是我们数据集的三个例子,IBM 是唯一一家检测到其中人脸的供应商。
IBM 的示例图像 # 356147

仅由 IBM 检测到面部的图像。
......
想要继续阅读,请移步至我们的AI研习社社区:http://www.gair.link/page/TextTranslation/884
更多精彩内容尽在 AI 研习社。
不同领域包括计算机视觉,语音语义,区块链,自动驾驶,数据挖掘,智能控制,编程语言等每日更新。
等你来读:
基于 OpenCV(C++/Python) 使用深度学习 进行人类姿态检测
如何在 Azure 上使用 Horovod 框架进行物体检测的分布式深度学习
基于 OpenCV 使用 YOLOv3 进行深度学习中的物体检测
亚马逊、谷歌、微软等各家公司人脸识别对比
斯坦福CS231n李飞飞计算机视觉经典课程(中英双语字幕+作业讲解+实战分享)
等你来译:
你能在 10 分钟之内解决人物检测的问题吗?
如何使用 OpenCV 编写基于 Node.js 命令行界面 和 神经网络模型的图像分类
深度学习来自监督的方法

时间:2018-09-12 23:50 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















